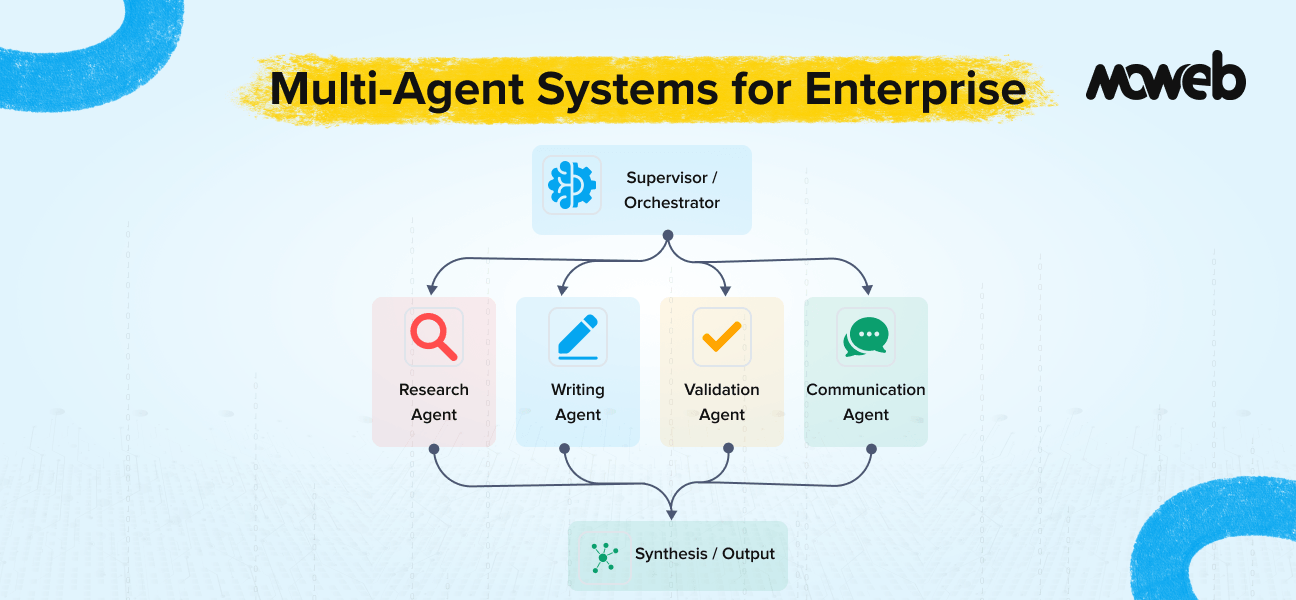
What is a multi-agent AI system? A multi-agent AI system (MAS) is an architecture in which multiple specialised AI agents work together to complete a complex workflow – each agent handling a defined sub-task, with an orchestration layer coordinating the sequence, managing state, routing outputs between agents, and handling failures and escalations. Unlike a single AI agent that must handle all aspects of a task within a single context, a multi-agent system decomposes complex goals into specialised sub-tasks that separate agents execute in sequence or in parallel, then combines their outputs into a coherent result. The key benefit is that specialisation and parallelisation together produce outcomes that exceed what any single agent can achieve with a single context window and a single set of tools.
When should an enterprise use multi-agent systems instead of single agents? Use multi-agent systems when: a workflow requires capabilities or tool access that cannot be combined into a single agent without creating an unmanageable context or permission scope; different sub-tasks require different specialist knowledge or different system integrations; parallel execution of independent sub-tasks would significantly reduce total completion time; or independent validation of outputs by a separate reviewer agent is required for quality or compliance reasons. These gains are real but task-dependent, not universal: Anthropic’s own research documents multi-agent architectures outperforming single agents by 90.2% on breadth-first research tasks where work can be parallelised at roughly 15x the token cost of a single-agent approach. The same research found that for tasks requiring tightly sequential reasoning, multi-agent coordination can perform 39–70% worse than a single agent, because inter-agent communication overhead exceeds the benefit. The architecture is a tool for specific problem shapes, not a universal performance upgrade.
Inquiries about multi-agent AI systems surged 1,445% between Q1 2024 and Q2 2025, according to Gartner. That number is not a measure of hype it is a measure of production reality. As of Q1 2026, multi-agent (3+ agent) orchestration accounts for 22% of enterprise agent deployments, projected to reach 45–50% by 2027 (cross-source 2026 enterprise data set spanning Gartner, McKinsey, IDC, Forrester, and S&P Global). The average Fortune 500 organisation runs 3.4 distinct AI agents in 2026, projected to reach 6–8 by 2027. Gartner predicts 40% of enterprise applications will feature task-specific AI agents by the end of 2026, up from less than 5% in 2025.
The adoption curve is real, but so is a sobering counter-statistic that the original framing of this opportunity tends to omit: Forrester and Anaconda’s 2026 research found that 88% of agent pilots never reach production, with evaluation gaps, governance friction, and model reliability cited as the top blockers. Separately, Gartner expects more than 40% of agentic AI projects to be cancelled by 2027 driven by escalating costs, unclear business value, and inadequate risk controls. The opportunity in multi-agent systems is genuine. So is the failure rate for organisations that adopt the architecture without the governance discipline it requires.
The shift from single agents to multi-agent systems is happening because single agents hit ceilings. They hit context window limits when tasks require processing more information than fits in a single prompt. They hit capability limits when different sub-tasks require different tools or different specialist knowledge. They hit accuracy limits when there is no mechanism for one agent to check another’s work. Multi-agent systems address all three ceilings – by distributing tasks across specialised agents, running sub-tasks in parallel, and building validation directly into the workflow architecture.
This guide explains how multi-agent systems work in enterprise deployments, the four architectural patterns that cover most production use cases, the governance requirements that regulated enterprises must address, and the decision framework for determining when a multi-agent architecture is the right choice and when a simpler single-agent approach is sufficient. For the foundational distinction between chatbots, copilots, and agents before moving to multi-agent architectures, see our guide to the difference between AI chatbot, copilot, and AI agent.
From Single Agent to Multi-Agent: Understanding the Transition
Before examining multi-agent architectures, it is worth being precise about what a single AI agent is and where it reaches its practical limits in enterprise contexts.
A single AI agent receives a goal, accesses a defined set of tools (APIs, databases, document retrieval systems), executes a sequence of steps using those tools, and produces a result. Its constraints are: the context window size determines how much information it can hold and process simultaneously; its tool set determines which external systems it can interact with; and its single execution thread means it processes sub-tasks sequentially, not in parallel.
For focused, well-defined tasks – drafting a document, answering a question from a knowledge base, processing a single record through a defined workflow – a single agent is the right architecture. The simplicity of a single agent reduces failure points, makes debugging straightforward, and keeps governance requirements manageable.
The ceiling appears when tasks grow in complexity along three dimensions.
Breadth: The task requires integrating information from many sources or taking actions across many systems. A single agent handling a complex enterprise workflow – gathering customer data from CRM, financial data from ERP, compliance status from GRC, recent communications from email, then synthesising a complete account briefing with recommended actions – may exceed practical context limits and tool permission scope in a single agent design.
Depth: Different sub-tasks within a workflow require genuinely different specialist capabilities. A content production workflow requires a research agent with web access, a writing agent with editorial knowledge, a fact-checking agent with source verification tools, and a formatting agent with publishing system access. Combining all four capabilities into a single agent creates an unwieldy context and dilutes each specialisation.
Quality assurance: High-stakes workflows benefit from independent verification – a separate agent reviewing the outputs of the primary agent before they are committed to action. Self-review within a single agent is less reliable than independent review by a separate agent because the same model that generated an error is less likely to detect it than a fresh agent approaching the output as a reviewer.
When a workflow hits these ceilings, multi-agent architecture is the correct design response. For the implementation roadmap and risk framework for enterprise AI agent deployments, generally the foundation that multi-agent systems build on, see our guide to AI agent development services: use cases, risks, and implementation roadmap.
How Multi-Agent Systems Work: The Core Concepts
Understanding multi-agent systems requires understanding five concepts that are specific to multi-agent architectures and absent from single-agent deployments.
Orchestration is the coordination layer that manages agent execution: deciding which agent runs when, routing outputs from one agent to the inputs of the next, managing parallel execution threads, handling errors and retries, and determining when the workflow is complete. Orchestration can be implemented as a dedicated orchestrator agent (an agent whose role is to direct other agents), as a defined workflow graph (a pre-specified sequence with conditional branching), or as a combination of both.
State management is the mechanism by which context is maintained and shared across agents in a workflow. Unlike a single agent that holds all context in its working memory, a multi-agent system must explicitly manage what information is passed between agents, what is persisted in shared state, and what each agent needs to know about the work already done by previous agents. Poor state management is the most common cause of multi-agent system failures in production.
Handoffs are the transfer points where one agent completes its sub-task and passes its output to the next agent. Handoff design – what information is transferred, in what format, and with what validation – is one of the most important architectural decisions in a multi-agent system. Most agent failures in production are not model capability failures; they are orchestration and context-transfer issues at handoff points.
Specialisation is the principle that each agent in a multi-agent system has a defined, limited role with a correspondingly limited tool set and permission scope. A research agent has access to web search and document retrieval but not to CRM write access. A communication agent can send emails but cannot access financial data. Specialisation is both an architectural efficiency principle (narrower scope produces higher quality within that scope) and a security principle (least-privilege access at the agent level).
Human-in-the-loop and human-on-the-loop are the two enterprise governance models for multi-agent systems. Human-in-the-loop requires human approval at defined decision points before the workflow proceeds – used for high-stakes, irreversible actions. Human-on-the-loop allows the workflow to proceed autonomously but with a human supervisor who can intervene if monitoring alerts indicate a problem. The trend in enterprise deployments in 2026 is toward human-on-the-loop for well-validated workflows and human-in-the-loop for novel or high-consequence decision points.
The Four Architectural Patterns for Enterprise Multi-Agent Systems
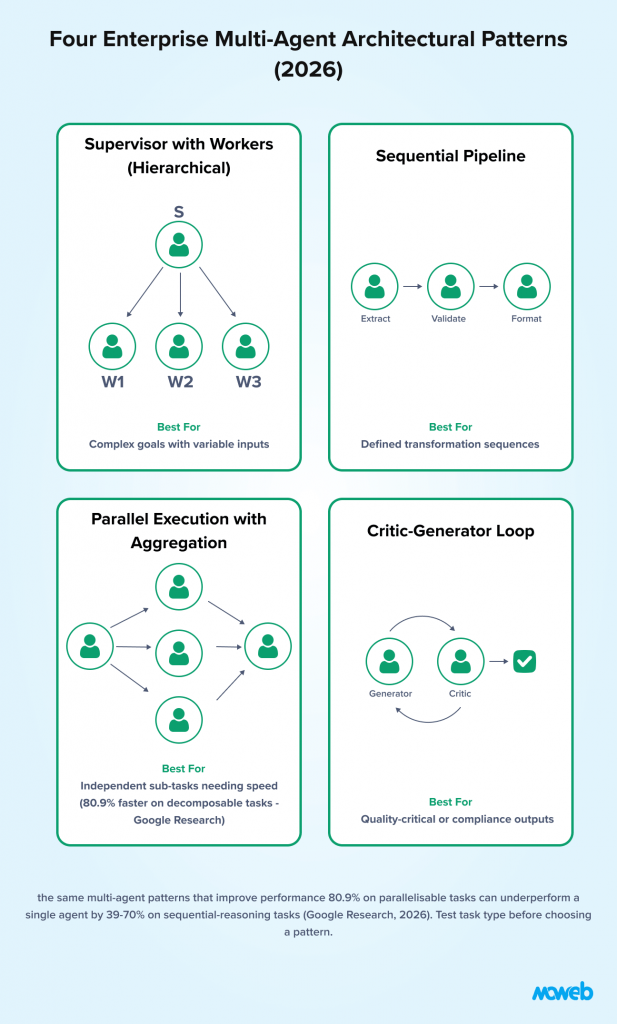
Most production enterprise multi-agent systems use one of four architectural patterns, or a combination of two.
Pattern 1: Supervisor with Worker Agents (Hierarchical)
A central supervisor agent receives the high-level goal, decomposes it into sub-tasks, assigns each sub-task to a specialised worker agent, monitors execution, and synthesises the outputs into a final result. The supervisor does not execute the sub-tasks itself – it manages the decomposition, delegation, and synthesis.
This is the most widely deployed pattern for enterprise automation workflows: procurement processing, customer account management, compliance checking, and report generation. The supervisor’s ability to dynamically decompose goals – rather than following a pre-specified workflow graph – makes it adaptable to varied inputs and edge cases that fixed workflows handle poorly.
The performance advantage can be significant, but it comes at a real cost that proposals should state explicitly. Anthropic’s own multi-agent Research architecture, a lead agent that plans strategy while 3 to 5 sub-agents gather data in parallel, with a separate citation pass for synthesis, outperformed single-agent Claude Opus 4 by 90.2% on internal breadth-first research evaluations. That performance gain came at roughly 15x the token cost of a single conversational turn. Separately, Google Research tested 180 different multi-agent configurations and found that for tasks genuinely decomposable into independent parallel pieces, multi-agent coordination improved performance by 80.9% over a single agent, but for tasks requiring tightly sequential reasoning, every multi-agent configuration tested performed 39% to 70% worse than a single agent, because inter-agent communication overhead exceeded any specialisation benefit. The supervisor pattern’s value is specific to genuinely decomposable, parallelisable work, not a general-purpose performance multiplier.
When to use it: When the task is complex enough to require multiple specialist capabilities, when different sub-tasks can be parallelised to reduce total completion time, and when the supervisor’s dynamic task decomposition is needed to handle variable inputs.
When not to use it: When the task is simple enough for a single agent, or when the overhead of orchestration adds latency that outweighs the benefit for time-sensitive applications.
Pattern 2: Sequential Pipeline
Agents execute in a defined sequence, each processing the output of the previous agent and passing its result to the next. There is no dynamic task decomposition – the workflow is pre-specified. Each stage applies a transformation, enrichment, or validation to the data before passing it downstream.
Document processing pipelines are the clearest example: an extraction agent pulls structured data from raw documents, a validation agent checks the extracted data against defined rules, an enrichment agent adds contextual information from related systems, and a formatting agent produces the final output in the required structure.
When to use it: When the workflow has a stable, well-defined sequence of transformations; when each stage’s output is the direct input to the next; and when the sequential nature of the task means parallelisation does not apply.
When not to use it: When the workflow requires dynamic adaptation based on intermediate results, or when stages can be parallelised to reduce latency.
Pattern 3: Parallel Execution with Aggregation
Multiple agents execute simultaneously on different sub-tasks or different portions of the input data, and an aggregator combines their outputs into a unified result. Parallel execution is appropriate when sub-tasks are independent and time reduction is a primary objective.
Research and synthesis workflows use this pattern: multiple research agents simultaneously gather information from different source types (web search, internal knowledge base, structured data, expert systems), and a synthesis agent combines their findings into a coherent output. The total elapsed time is determined by the slowest parallel agent rather than the sum of all agents, which can reduce wall-clock completion time by 60-80% compared to sequential execution.
When to use it: When sub-tasks are genuinely independent of each other; when total completion time is a primary success criterion; and when the aggregation logic is well-defined and does not require complex reasoning about conflicting outputs from parallel agents. This is the pattern that benefited most clearly in Google Research’s testing, an 80.9% performance improvement on genuinely independent, decomposable sub-tasks. The same testing is also the clearest warning against applying this pattern to sequential-reasoning tasks, where it consistently underperformed a single agent.
When not to use it: When sub-tasks are interdependent and need to share intermediate results; or when parallel execution complexity and cost outweigh the time benefit for simple workflows.
Pattern 4: Critic-Generator (Self-Improving Loop)
A generator agent produces an initial output. A separate critic (or reviewer) agent evaluates that output against defined quality criteria and provides structured feedback. The generator iterates based on the feedback. The loop continues until the output meets the quality threshold or a maximum iteration count is reached.
This pattern addresses the fundamental limitation of single-agent self-review: the same model that generates an error is less likely to detect it. A separate critic agent, prompted to identify specific failure modes rather than to produce or improve the output, consistently outperforms the generator’s self-review for catching logical errors, factual inconsistencies, compliance violations, and format deviations.
Code generation, compliance document drafting, and analytical report production are the highest-value enterprise applications of this pattern. For regulated outputs where quality is a compliance requirement, the critic-generator architecture provides a documented quality assurance step that single-agent generation cannot.
When to use it: When output quality is critical and cannot be fully validated through automated rule-checking alone; when independent review adds meaningful value beyond what the generator can achieve through self-revision; and when the iteration cost (additional API calls and latency) is justified by the quality improvement.
The A2A Protocol: How Agents from Different Systems Communicate
A significant development in enterprise multi-agent architecture in 2026 is the maturation of the Agent-to-Agent (A2A) protocol. A2A was introduced by Google in April 2025 it is a Google-originated protocol, not a vendor-neutral standard from inception, though it has since been opened for broad industry contribution. It uses JSON-RPC 2.0 over HTTPS, with “Agent Cards” that describe each agent’s capabilities and connection information. Over 150 organisations now support A2A, including every major hyperscaler. Google’s own framing distinguishes the two protocols with a car repair analogy: MCP connects the mechanic (agent) to their tools; A2A enables the customer to communicate with mechanics and lets mechanics coordinate with each other.
Before A2A, multi-agent systems required all agents to be built on the same framework: LangGraph agents could not natively collaborate with CrewAI agents, and neither could easily integrate with commercial agent platforms from enterprise software vendors. This forced enterprises to commit to a single orchestration framework for their entire multi-agent portfolio – a significant constraint as different use cases are best served by different frameworks.
A2A addresses this by defining a standardised communication protocol: how agents advertise their capabilities, how they receive and acknowledge task assignments, how they report progress and results, and how they signal failures and escalations. An agent built on LangGraph can receive task assignments from an orchestrator built on CrewAI, provided both implement the A2A specification.
For enterprise architects, A2A has practical implications: multi-agent systems no longer require framework homogeneity, commercial AI agent platforms from enterprise software vendors (Salesforce Agentforce, ServiceNow Otto, Microsoft Copilot Studio) can participate in custom multi-agent workflows alongside internally developed agents, and vendor lock-in at the orchestration framework level is reduced. Gartner’s January 2026 research formalises this expectation: by 2027, over 50% of enterprise AI agents will rely on standardised frameworks like MCP or A2A for secure, cross-system interoperability, and Gartner separately forecasts that 60% of early agentic orchestration implementations will fail to meet performance or cost expectations by 2030, specifically because enterprises underestimate the integration, governance, and talent requirements involved. This connects directly to the MCP (Model Context Protocol) layer covered in our guide to what MCP is and why it matters for enterprise AI agents. Where MCP standardises how agents connect to tools and data sources, A2A standardises how agents connect to each other. Together, they form the interoperability foundation that makes multi-agent systems composable across vendors and frameworks.
Gartner’s “Backend for Agent” (BFA) pattern, deploying scoped MCP servers that expose only the tool metadata and permissions a specific agent needs, has emerged as the recommended approach for preventing context window overload and the reasoning degradation that occurs when agents have access to too many overlapping tools.
Orchestration framework choice is a related but separate decision from protocol adoption. As of 2026, LangGraph has the largest production deployment footprint for enterprise multi-agent systems and is the default choice for complex, stateful workflows requiring explicit control, retries, and human-in-the-loop checkpoints. CrewAI offers the fastest path from prototype to demo for role-based agent teams but carries up to 3x the token overhead of LangGraph on equivalent workflows and trails on production observability. Anthropic’s Claude Agent SDK, the same architecture underlying Claude Code, has become the fastest-growing framework for Anthropic-native production agents, with native support for hooks, MCP, skills, and subagents. Microsoft’s AutoGen remains strong for research and academic multi-agent debate patterns but sees less production adoption than LangGraph or CrewAI. Framework choice affects benchmark performance by up to 30 percentage points on identical underlying models it is not a marginal decision.
Governance Requirements for Enterprise Multi-Agent Systems
Multi-agent systems have governance requirements that exceed those of single agents because their complexity, autonomy, and potential impact are greater. The four governance dimensions that enterprise deployments must address are covered in detail in our guide to AI governance for LLMs and enterprise agents. Here is how those requirements apply specifically to multi-agent architectures.
Permission scoping at the agent level. Each agent in a multi-agent system should have the minimum permissions required for its specific sub-task. The research agent does not need write access to the CRM. The communication agent does not need access to financial data. Principle of least privilege must be applied at the agent level, not just the system level. In practice, this means maintaining a permission matrix that maps each agent to its authorised tool set and data access, reviewed and approved before any agent goes to production.
Audit trail across the full workflow. The audit trail for a multi-agent workflow must capture the actions of every agent in the chain, not just the final output. For compliance and incident investigation, the ability to reconstruct the complete reasoning and action sequence what each agent did, what data it accessed, what output it produced, and what it passed to the next agent is essential. Standard logging for multi-agent systems must be designed to capture the complete inter-agent communication record, not just entry and exit events. The audit trail architecture for multi-agent systems follows the same principles as single-agent governance. See our guide to building secure enterprise chatbots with audit trails and compliance for the detailed implementation.
Escalation design for unexpected situations. Multi-agent systems encounter situations that neither the orchestrator nor the individual agents were designed for. The governance framework must define: what constitutes an out-of-scope situation, how each agent recognises and signals it, how the orchestration layer routes escalations to human review, and what the human reviewer is expected to decide. Undefined escalation behaviour where an agent proceeds autonomously when it should have escalated is among the most common sources of multi-agent governance failures in production.
Cost monitoring and circuit breakers. Multi-agent systems can generate substantially more LLM API calls than single-agent systems, particularly in critic-generator loops and parallel execution patterns. Anthropic’s own Research architecture runs at roughly 15x the token cost of a single chat turn; without monitoring, this multiplier compounds quickly across concurrent workflow executions. Without cost monitoring and circuit breakers (automatic halts when cost exceeds a defined threshold per workflow execution), runaway multi-agent workflows can generate unexpected and significant API costs. Cost monitoring at the workflow level is an operational requirement, not an optional enhancement. Industry data from 2026 puts LLM costs at 40–60% of total agent operating expenditure; prompt caching can reduce this by 80–90% on workloads with stable, repeated context, and should be treated as a default cost-control measure rather than an optimisation to revisit later.
When to Use Multi-Agent vs Single Agent: A Decision Framework
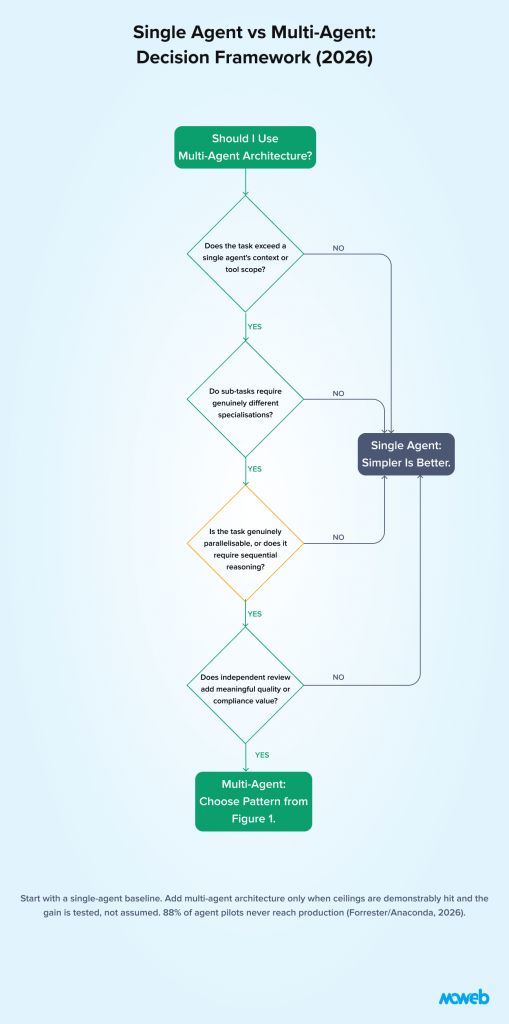
Apply these four questions in sequence to determine whether a multi-agent architecture is justified for a specific use case.
Question 1: Does the task exceed a single agent’s practical context or tool scope? If the workflow requires processing more information than fits in a single context window, or integrating more tool categories than a single agent can handle cleanly, multi-agent architecture is likely warranted. If a single agent can handle the full task with a manageable context and tool set, a single agent is simpler and should be preferred.
Question 2: Do different sub-tasks require genuinely different specialisations? If different stages of the workflow require meaningfully different capabilities (research vs writing vs validation vs distribution), specialised agents produce better outcomes than a single agent performing all roles. If the task is more uniform – a consistent application of the same capability to different inputs – a single agent with high-quality prompting may be sufficient.
Question 3: Would parallelisation significantly reduce total completion time? If this question matters more than the original framing suggests. If sub-tasks are genuinely independent and can run simultaneously, multi-agent parallel execution can deliver substantial time and quality gains. Google Research documented an 80.9% improvement on this category of task. But if the workflow requires step-by-step reasoning where each step depends on the prior step’s output, multi-agent decomposition can perform 39–70% worse than a single agent on the same testing, because coordination overhead exceeds any specialisation benefit. Test which category your workflow falls into before committing to a parallel architecture.
Question 4: Does independent quality review add meaningful value? If the output quality or compliance requirement justifies a separate reviewer agent, the critic-generator pattern is warranted. If automated testing or human review at the output stage is sufficient, the added complexity of an in-workflow critic may not be justified.
If the answers to all four questions are no: use a single agent. If one or more answers are yes: the specific combination of yes answers determines which multi-agent pattern applies.
One additional practical filter before committing budget: given that 88% of agent pilots never reach production (Forrester/Anaconda, 2026) and Gartner expects over 40% of agentic AI projects to be cancelled by 2027, treat a multi-agent proposal with the same scrutiny as any other capital commitment. Require a named single-agent baseline to be tested first, and require the multi-agent proposal to demonstrate, on your own representative tasks, that it outperforms that baseline by a margin that justifies the added governance and cost overhead.
Frequently Asked Questions About Multi-Agent Systems
What is the difference between a multi-agent system and a single AI agent? A single AI agent handles all aspects of a task within a single context window using a single tool set. A multi-agent system distributes the task across multiple specialised agents that each handle a defined sub-task, with an orchestration layer coordinating their execution. Multi-agent systems handle complexity that exceeds a single agent’s practical limits: tasks requiring more context than a single window can hold, tasks requiring different specialist capabilities in different stages, and tasks where independent validation improves quality or compliance.
What is agent orchestration? Agent orchestration is the coordination layer that manages multi-agent workflow execution: deciding which agent runs when, routing outputs between agents, managing state across the workflow, handling parallel execution, and escalating failures to human review. Orchestration can be implemented as a dedicated orchestrator agent, a workflow graph, or a combination. Leading orchestration frameworks in 2026 are LangGraph (largest production footprint, best for complex stateful workflows), CrewAI (fastest prototype-to-demo path, but up to 3x the token overhead of LangGraph), the OpenAI Agents SDK, and Anthropic’s Claude Agent SDK (the fastest-growing framework for Anthropic-native production agents). Framework choice can affect benchmark performance by up to 30 percentage points on identical underlying models.
What is the A2A protocol and why does it matter for enterprise? The Agent-to-Agent (A2A) protocol, introduced by Google in April 2025, is a communication standard allowing AI agents from different vendors and frameworks to discover each other, communicate task assignments, and share outputs within a shared workflow. Over 150 organisations now support it, including every major hyperscaler. For enterprises, A2A means multi-agent systems no longer require framework homogeneity commercial AI agent platforms from enterprise software vendors can participate alongside custom-built agents. Combined with MCP for tool connectivity, A2A enables composable multi-agent architectures across vendors. Gartner projects over 50% of enterprise AI agents will rely on MCP or A2A for interoperability by 2027.
How do you ensure multi-agent systems do not take unauthorised actions? Through permission scoping at the agent level (each agent has only the permissions required for its specific sub-task), human-in-the-loop gates at high-stakes decision points, defined escalation paths for out-of-scope situations, and immutable audit logging of every action taken across the full workflow. The governance framework for multi-agent systems must be designed before deployment, not retrofitted after a governance incident.
What are the most common failure modes in enterprise multi-agent deployments? The most common failure is not model capability failure it is orchestration and context-transfer failure at handoff points between agents. The second most common is state management failure: agents working with incomplete or inconsistent context because the shared state was not designed carefully. Third is escalation failure: agents that encounter out-of-scope situations and proceed autonomously rather than escalating to human review. At the programme level, the dominant failure mode is simpler: 88% of agent pilots never reach production (Forrester/Anaconda, 2026), with evaluation gaps cited by 64% of leaders, governance friction by 57%, and model reliability by 51% as the top blockers. Most production multi-agent failures are architectural and organisational, not model-level.
When is a multi-agent system overkill for an enterprise use case? A multi-agent system is overkill when: a single agent can handle the full task with a manageable context and tool set; when the workflow is simple enough that the orchestration overhead exceeds the performance benefit; when the use case is new, and the team lacks experience debugging multi-agent failure modes; or when latency requirements make orchestration overhead unacceptable. Start with a single agent. Add multi-agent architecture only when the single agent demonstrably cannot achieve the required performance or quality.
Conclusion: Multi-Agent Architecture Is the Right Choice for the Right Problems
Multi-agent systems are not universally better than single agents. They are better for a specific class of problems: those that exceed a single agent’s practical context and capability limits, benefit from specialisation and parallelisation, and require independent validation built into the workflow rather than applied after the fact.
The enterprises generating genuine performance gains from multi-agent deployments gains that, on the right task category, can exceed 80% over single-agent baselines did not simply add more agents to their existing workflows. They identified the specific problems where single agents were hitting ceilings, designed agent teams that addressed those specific ceilings, and implemented the governance framework permission scoping, state management, escalation design, and cost monitoring that makes multi-agent systems safe and reliable in production.
The governance complexity of multi-agent systems is real. The performance benefit is equally real, but only for the problems that justify the architecture, and only when the cost (in tokens, latency, and operational complexity) is weighed against that benefit honestly. With 88% of agent pilots failing to reach production and Gartner projecting over 40% of agentic AI projects cancelled by 2027, the organisations succeeding with multi-agent architecture are disproportionately the ones that ran this cost-benefit analysis before building, not after a failed pilot. The decision framework in this guide is designed to help enterprises identify those problems precisely and avoid building multi-agent complexity into workflows that do not need it.
Moweb’s AI Agents & Intelligent Automation practice designs and builds both single-agent and multi-agent systems for enterprise clients – including orchestration architecture, permission framework design, state management, and the governance and monitoring infrastructure that production deployment requires. Talk to us about your agent architecture requirements.
Found this post insightful? Don’t forget to share it with your network!