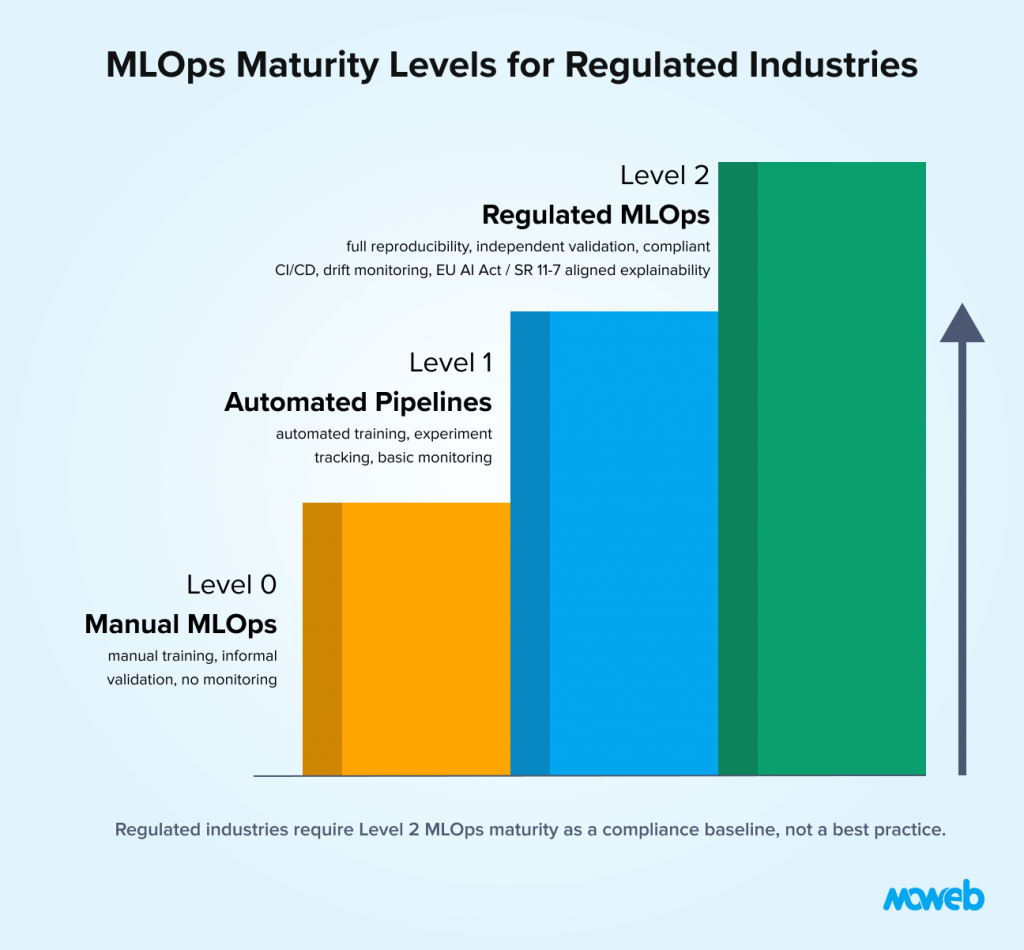
What is MLOps in regulated industries? MLOps (Machine Learning Operations) in regulated industries applies the standard disciplines of machine learning operationalisation – experiment tracking, model versioning, pipeline automation, deployment, and monitoring – within the additional constraints imposed by regulatory frameworks such as SR 11-7 (banking), 21 CFR Part 11 (pharma), HIPAA (healthcare), the EU AI Act (mandatory for high-risk AI systems under Annex III as of 2025),, and sector-specific model risk management guidelines. The practical effect is that every decision made during model development, validation, and deployment must be documented, reproducible, auditable, and in some cases pre-approved by regulators before the model can influence regulated decisions.
What makes MLOps harder in regulated industries? Three requirements that are optional or informal in general enterprise MLOps become mandatory and auditable in regulated environments: full reproducibility (every training run must produce the same model given the same code and data, so that auditors can validate exactly what was deployed), model explainability (the model’s decisions must be interpretable by non-technical stakeholders including regulators and affected parties), and independent validation (for high-risk models, the validation function must be separated from the development function – the team that builds the model cannot be the sole team that validates it). These three requirements add significant engineering overhead that organisations unprepared for them consistently underestimate.
Building a machine learning model that performs well in a notebook is a solved problem. Building a model that a regulator will accept, that a compliance team will approve, and that will maintain its performance reliably over three years in production – that is the actual challenge in financial services, healthcare, pharmaceuticals, and government.
The gap between “this model works” and “this model meets our regulatory obligations” is almost entirely filled by MLOps: the practices, tools, and governance structures that operationalise machine learning systems at enterprise scale. In regulated industries, that gap is wider and more consequential than in unregulated contexts. Getting it wrong means failed audits, regulatory sanctions, and in some cases, being required to withdraw a model from production and repay affected parties. with potential liability for decisions made during the non-compliant period.
This guide is for ML engineers, data scientists in enterprise roles, and technical leads in regulated industries who need to build MLOps practices that satisfy both engineering quality standards and the specific compliance requirements of their regulatory context.
For the strategic decision of whether to invest in predictive ML or generative AI first, see our guide to generative AI vs predictive AI: where to invest first.
What Changes When You Are in a Regulated Industry
Before getting into specific practices, it is worth being precise about what regulation adds to standard MLOps. The changes are not arbitrary complexity – they map directly to the risks that regulators are trying to control.
Reproducibility becomes mandatory, not optional. In a standard enterprise ML deployment, if you cannot exactly reproduce a training run, you might lose some experiment tracking fidelity. In a regulated environment, if you cannot reproduce the exact model that was deployed, you cannot respond to a regulatory examination that asks you to demonstrate that the model in production matches the model that was approved. This means that not just code, but data versions, environment configurations, random seeds, and all preprocessing steps must be tracked and replicable with sufficient precision to produce bit-for-bit (or statistically equivalent) model outputs.
Model explainability becomes a compliance requirement, not a quality preference. The EU AI Act’s high-risk tier requires explainability for models used in credit, employment, healthcare, and similar contexts. SR 11-7 (the US Federal Reserve’s model risk management guidance) requires that model developers be able to explain the conceptual framework, assumptions, and limitations of their models to non-technical stakeholders. FDA Software as a Medical Device (SaMD) guidance similarly requires that clinical decisions informed by AI can be explained to patients and clinicians, with documented algorithmic transparency. In each case, “the model is accurate” is not a sufficient explanation.
Independent validation becomes structurally required. In standard enterprise ML, the team that builds a model typically validates it themselves before deployment. In regulated environments, particularly financial services (SR 11-7), there is an explicit requirement for independent model validation: the validation function must be separate from the development function, with its own standards, methodologies, and escalation path. This is not just a quality best practice – it is an audit requirement that must be demonstrated with organisational structure and documentation, not just informal peer review.
Change management requires formal approval gates. In a standard enterprise CI/CD pipeline, a model update that passes automated tests can be deployed without manual approval. In regulated environments, material changes to models – new features, retrained weights, changed decision thresholds – typically require formal documentation, validation, and in some cases regulatory notification before deployment. What constitutes a “material change” needs to be defined in advance as part of the MLOps governance framework.
Understanding these four changes shapes every specific practice recommendation that follows.
Practice 1: Reproducible Training Pipelines
Reproducibility in regulated environments requires a more disciplined approach than simply using version control for code. The full set of inputs to a training run must be frozen and versioned together.
Data versioning is the most commonly overlooked component. Your training dataset is not static – data pipelines update it continuously. A model trained on “the customer transaction data as of Q1 2025” and a model trained on “the customer transaction data as of Q2 2025” are different models, even if the code and configuration are identical. For regulated models, the exact dataset used for training (not just a description of it) must be versioned and retrievable. Tools like DVC (Data Version Control), Delta Lake with time travel, or Databricks’ managed feature stores provide the data versioning infrastructure needed.
Moweb’s Data Engineering & Foundations practice implements the data pipeline and versioning infrastructure that regulated ML reproducibility requires.
Environment reproducibility requires containerised training environments using Docker or a managed container service. The container image used for a training run must be versioned alongside the code and data. Python package versions, system libraries, and CUDA versions must be pinned and recorded. The common practice of using “latest” versions of dependencies in training environments is incompatible with regulated MLOps.
Random seed management is a specific requirement for models that involve randomisation (neural networks, random forests, stochastic optimisation). Every source of randomness in the training pipeline must be seeded with a fixed, recorded value to ensure the same model is produced from the same inputs. This applies to data shuffling, weight initialisation, dropout, and any sampling operations.
Experiment tracking infrastructure is not optional in regulated contexts. Tools like MLflow, Weights & Biases, or Neptune must be configured to log every hyperparameter, metric, and artifact from every training run before that run completes. The experiment tracking system must be treated as a compliance record: its data must be immutable after creation and retained for the same period as other model governance documentation.
Practice 2: Model Versioning and the Model Registry
A model registry is the central governance artifact for a regulated ML programme. It is not just a storage location for model artifacts – it is the record of what models have been approved, deployed, and retired, with the documentation and validation evidence attached to each.
A production-grade model registry for regulated industries records for each model version:
- The complete training lineage: code version (git commit hash), data version, environment version, hyperparameters, and training metrics
- The validation report: who validated the model, what validation methodology was used, what the validation results were, and what limitations were identified
- The approval record: who approved the model for production deployment, on what date, and under what conditions
- The deployment history: which environments the model has been deployed to, at what times, and which model version it replaced
- The change classification: whether the update constitutes a material change requiring formal approval or an immaterial update that can proceed through automated gates
- The monitoring baseline: the performance metrics at the time of deployment that will serve as the baseline for ongoing drift detection
Tools like MLflow Model Registry, AWS SageMaker Model Registry, and Azure ML Model Registry all provide the infrastructure for this. The governance layer (who can approve, what evidence is required, what constitutes a material change) must be configured by the implementing organisation rather than provided by the tool.
Practice 3: Explainability Frameworks
Model explainability in regulated industries is not a single technique – it is a layered framework that addresses different audiences with different needs.
Global explainability describes the model’s overall behaviour: which features are most important to its predictions across the population, what the general decision boundary looks like, and what types of inputs tend to produce different classes of output. For regulators and senior stakeholders, global explainability demonstrates that the model is making decisions based on conceptually sound features rather than spurious correlations.
Local explainability describes the model’s behaviour for a specific prediction: why did this model assign this score to this individual? For regulated models that affect individual outcomes (credit decisions, insurance pricing, clinical risk scores), local explainability is required to satisfy the right to explanation provisions in GDPR, the adverse action notice requirements under the US Equal Credit Opportunity Act, and the clinical accountability requirements under healthcare regulation.
The most widely deployed explainability tools in regulated enterprise contexts are:
- SHAP (SHapley Additive exPlanations): Provides both global feature importance and local per-prediction explanations grounded in game theory. Widely accepted by regulators in financial services and healthcare as a methodologically sound approach. Computationally expensive at scale but the standard choice for high-stakes models.
- LIME (Local Interpretable Model-agnostic Explanations): Faster than SHAP for local explanations, trades some theoretical rigour for computational efficiency. Used where per-prediction latency constraints make SHAP impractical.
- Inherently interpretable models: For use cases where full flexibility of a complex model is not required (some credit scoring applications, certain clinical risk scores), decision trees, logistic regression, and scorecard models provide inherent transparency that SHAP and LIME do not need to supplement. Regulators in some contexts specifically prefer these.
The choice of explainability approach should be documented in the model’s design specification and validated as part of the independent validation process.
Practice 4: Independent Model Validation
Independent validation is the most structurally challenging MLOps requirement in regulated industries because it requires organisational design changes, not just tooling changes.
The independent validation function must have:
- Organisational separation from the model development team. In large regulated institutions, this is typically a dedicated Model Risk Management (MRM) function. In smaller organisations, it may be achieved through external validation by a third party.
- Its own validation standards. The validation function does not simply verify that the developer’s tests pass – it applies its own methodology to assess the model’s conceptual soundness, empirical performance, and limitations. This typically includes benchmarking the model against alternative approaches, testing performance on independent holdout data that the development team did not use, and stress-testing the model against scenarios not represented in the training data.
- A documented escalation path. If the validation function identifies material issues with a model, there must be a defined process for escalation, remediation, and re-validation. The escalation path should not run through the model development team.
- Documented validation reports that become part of the model’s governance record and are available to regulators on request.
InterpretML (Microsoft): Combines EBM (Explainable Boosting Machines) with SHAP and LIME wrappers, providing a unified explainability interface increasingly adopted in regulated financial and healthcare contexts.
For organisations that do not have an internal Model Risk Management function, third-party independent validation is an alternative. It is more expensive per model but avoids the overhead of building and maintaining an internal MRM capability.
Practice 5: Continuous Monitoring and Drift Detection

All ML models degrade over time as the data they encounter in production diverges from the data they were trained on. In regulated industries, model degradation is not just a quality problem – it is a compliance problem. SR 11-7 explicitly requires “ongoing monitoring” of model performance. The EU AI Act (Article 72) requires that high-risk models are subject to mandatory post-market monitoring by the deploying organisation, with documented incident reporting obligations.
An effective monitoring framework for regulated ML systems covers four distinct types of drift:
Data drift measures changes in the statistical distribution of input features. If the distribution of transaction amounts, customer ages, or loan-to-value ratios in production data shifts significantly from the training distribution, the model’s calibration assumptions may no longer hold. Data drift monitoring uses statistical tests (Population Stability Index, Kullback-Leibler divergence, Kolmogorov-Smirnov test) applied to feature distributions on a regular cadence.
Prediction drift measures changes in the distribution of model outputs. If a credit scoring model that previously produced scores averaging 680 is now averaging 720, something has changed – either the input population has changed, or the model is behaving differently. Prediction drift monitoring tracks output distributions over time and alerts when shifts exceed defined thresholds.
Performance drift measures degradation in model accuracy metrics against a ground truth label. This is the most direct measure of model quality but requires waiting for ground truth outcomes to materialise, which introduces a lag. For models where outcomes are observable quickly (fraud detection, near-term churn), performance drift can be monitored with low lag. For models with longer outcome horizons (multi-year credit defaults, annual churn), performance drift monitoring requires a proxy metric or a backtesting approach.
Concept drift is the most subtle form of drift: the underlying relationship between features and outcomes changes, even if the feature distributions do not. Rising interest rate environments change the relationship between payment history and default risk. Pandemic conditions change the relationship between clinical features and disease outcomes. Concept drift is hardest to detect automatically and often requires periodic expert review alongside statistical monitoring.
Monitoring results should trigger a defined escalation process. A common framework uses three levels: a warning threshold that triggers an investigation, a control threshold that triggers a formal model review, and a suspension threshold that triggers model withdrawal pending re-validation.
For the broader governance framework that covers model drift monitoring alongside access controls, audit trails, and regulatory compliance for LLMs, see our guide to AI governance for LLMs and enterprise agents.
Practice 6: CI/CD Pipelines for ML in Regulated Contexts
Continuous integration and continuous delivery for ML systems in regulated environments require additional gates beyond standard software CI/CD.
A regulated ML CI/CD pipeline typically includes the following gates, in addition to standard code quality and testing checks:
Data validation gate: Before a training pipeline run, automated checks verify that the input data meets defined quality standards: no unexpected nulls in critical fields, no out-of-range values, consistent schema with the expected version, and no evidence of data leakage between training and test sets. Training runs that fail data validation do not proceed.
Model performance gate: After training, automated evaluation compares the new model’s performance against the baseline and against the currently deployed model on a standard holdout set. Deployment is blocked if the new model does not meet the minimum performance thresholds defined in the governance framework.
Change classification gate: The pipeline automatically classifies the proposed update according to the organisation’s materiality framework: is this a material change requiring formal approval, or an immaterial update that can proceed through automated deployment? Material changes are flagged for human review before proceeding.
Explainability validation gate: For models subject to explainability requirements, the pipeline generates SHAP or LIME explanations for a sample of the test data and verifies that explanation quality metrics (stability, fidelity) meet defined thresholds.
Compliance documentation gate: Before deployment to production, the pipeline automatically generates the model documentation required by the governance framework (training metadata, performance metrics, data lineage, environment version) and attaches it to the model registry record.
Tools commonly used to implement regulated ML CI/CD pipelines include Kubeflow Pipelines, Apache Airflow, MLflow Projects, AWS SageMaker Pipelines, and Azure ML Pipelines. The tool choice matters less than the governance layer built on top of it. For realistic cost expectations before committing to a regulated ML programme, see our guide to what an AI proof of concept costs in 2026.
Practice 7: Model Retirement and Documentation
Every model has a lifecycle end. In regulated environments, retiring a model is as consequential as deploying one and requires the same level of documentation discipline.
Model retirement documentation should record: the date of retirement, the reason for retirement (superseded by a better model, business use case discontinued, performance degradation beyond acceptable thresholds, regulatory requirement change), the model that replaced it (if applicable), any data or decisions made by the model during its active period that may require retrospective review, and the retention period for model artifacts (code, data, trained weights, experiment logs) after retirement.
Retention of model artifacts after retirement is a regulatory requirement in most regulated industries. The model artifacts must be retained for a period sufficient to respond to a regulatory examination, litigation, or data subject access request that relates to decisions made during the model’s active period. Typical retention periods range from five to seven years for financial services models (jurisdiction-dependent) to seven to ten years for pharmaceutical clinical trial models and regulated healthcare AI, with some EU AI Act obligations extending to the model’s full operational lifecycle plus post-retirement review periods.
| MLOps Capability | Tool Options | Regulated-Specific Requirement |
| Experiment tracking | MLflow, Weights & Biases, Neptune | Immutable records, long-term retention |
| Data versioning | DVC, Delta Lake, Databricks Feature Store | Exact dataset reproducibility |
| Model registry | MLflow Model Registry, SageMaker Model Registry | Approval workflow, validation evidence storage |
| Pipeline orchestration | Kubeflow, Airflow, SageMaker Pipelines | Audit-logged runs, reproducible execution |
| Model deployment | Seldon, BentoML, SageMaker Endpoints | Blue/green with rollback, canary deployment |
| Monitoring | Evidently AI, Arize AI, WhyLabs, Fiddler | Data drift, prediction drift, performance drift |
| Explainability | SHAP, LIME, InterpretML | Per-prediction and population-level explanations |
| Feature store | Feast, Tecton, Databricks Feature Store | Point-in-time correctness for training and serving |
The most important architectural principle across all tool choices: every operation that has compliance implications must produce an immutable, timestamped record that is retained for the defined period and accessible to authorised reviewers without requiring the cooperation of the model development team.
Regulatory Alignment by Industry
The specific compliance requirements vary by regulatory context. Here is how the practices above map to the major regulatory frameworks:
Financial services (SR 11-7, SS1/23 UK PRA, EBA Guidelines on Internal Models): Requires independent validation, conceptual soundness documentation, ongoing performance monitoring, and formal approval for material model changes. The US Federal Reserve’s SR 11-7 guidance is the most widely referenced standard globally for financial model risk management.
Healthcare and clinical AI (FDA SaMD guidance, NICE Evidence Standards Framework, MDR): AI systems used as Software as a Medical Device (SaMD) face device-level regulatory requirements including pre-market notification or clearance in the US, CE marking in the EU, and adherence to IEC 62304 for software lifecycle processes. Performance monitoring post-deployment is a regulatory condition of approval.
Pharmaceutical and clinical trials (21 CFR Part 11, ICH E6 GCP, EU GMP Annex 11): Models used in clinical trial analysis or quality-critical manufacturing processes must demonstrate validation under 21 CFR Part 11 (US) or EU GMP Annex 11 (EU). This requires validation documentation covering installation qualification, operational qualification, and performance qualification – a more formal validation framework than typical enterprise ML.
Insurance (EIOPA Guidelines, Lloyd’s Market Association guidance): Actuarial models and pricing models face proportional requirements aligned with SR 11-7 principles but adapted to insurance regulation. UK and EU regulatory guidance specifically addresses algorithmic pricing models and their fairness implications.
EU AI Act (cross-sector, high-risk systems): Organisations deploying AI in any of the high-risk categories defined under Annex III including credit scoring, employment decisions, critical infrastructure, and clinical AI must comply with conformity assessment, technical documentation, human oversight, and post-market monitoring obligations that map directly onto the MLOps practices in this guide.
Moweb’s Machine Learning & MLOps practice works across all four regulatory contexts, and our AI Security & Governance practice handles the governance and compliance documentation layer that regulated MLOps requires.
Frequently Asked Questions About MLOps in Regulated Industries
What is the difference between MLOps in regulated and non-regulated environments? In non-regulated environments, MLOps best practices are adopted primarily for quality and efficiency: faster model deployment, better reproducibility, more reliable monitoring. In regulated environments, the same practices become compliance requirements: reproducibility is required for regulatory examination, monitoring is mandated by frameworks like SR 11-7, independent validation is structurally required, and change management requires formal approval gates. The engineering practices are similar; the governance overhead is significantly greater and the consequences of gaps are regulatory rather than just operational.
What is SR 11-7 and does it apply to my organisation? SR 11-7 is the US Federal Reserve’s Supervisory Guidance on Model Risk Management, issued in 2011 and still the primary standard for model risk management in US banking and financial services. It applies directly to US bank holding companies supervised by the Federal Reserve. Its principles have been adopted more broadly across the financial services industry globally, including by insurance companies, asset managers, and financial market infrastructure, even where not formally mandated. If your organisation uses models to make or inform significant financial decisions and operates in a regulated financial services context, SR 11-7 principles are likely applicable.
What does model explainability mean in practice for a credit model? For a credit scoring model, explainability in practice means two things. At the population level (global explainability), it means being able to explain to a regulator which features drive the model’s scores and demonstrating that those features are conceptually sound and do not produce discriminatory outcomes. At the individual level (local explainability), it means being able to provide an adverse action notice to an applicant who was declined, stating which factors most negatively affected their score — a legal requirement under the US Equal Credit Opportunity Act and similar regulations in other jurisdictions. SHAP values are the most widely accepted methodology for producing these individual-level explanations in a form that satisfies regulatory requirements.
How frequently should regulated ML models be retrained? Retraining frequency should be driven by monitoring data, not by a fixed schedule. The monitoring framework should define the performance thresholds that trigger a retraining evaluation. In practice, financial services fraud detection models may need quarterly retraining as fraud patterns evolve. Credit risk models are often retrained annually with the cycle aligned to annual data vintage refreshes. Clinical risk models are retrained when there is evidence of population shift or changes in clinical practice that affect the relationship between features and outcomes. The governance framework should define the retraining trigger criteria, the validation requirements for a retrained model, and whether a retrained model constitutes a material change requiring formal approval.
What is a feature store and why does it matter for regulated MLOps? A feature store is a centralised repository for the feature transformations used in ML models, ensuring that the same features are computed consistently both during model training and during model serving in production. Without a feature store, it is common for models to be trained on one version of a feature (computed by the data science team’s notebook) and served on a different version (computed by a production engineering team’s microservice). This training-serving skew is a common source of unexplained model performance degradation in production. In regulated environments, feature store architecture also supports point-in-time correctness: the ability to reconstruct the exact feature values that the model had access to at the time it made a specific prediction, which is essential for regulatory examination of historical decisions.
What is model drift and what triggers a formal review in regulated industries? Model drift is the degradation of a model’s performance over time as production data diverges from training data. In regulated environments, formal review thresholds should be defined in the model’s governance documentation before deployment. A common framework uses three trigger levels: a warning level (typically 10-15% degradation in a primary metric) that initiates an investigation, a control level (typically 20-25% degradation) that initiates a formal model review and may require stakeholder notification, and a suspension level (typically 30%+ degradation or a specific failure condition) that triggers model withdrawal pending re-validation. The specific thresholds should be calibrated to the risk profile of the model and the regulatory requirements of the use case.
How do we handle model governance when using third-party AI models or APIs? Third-party AI models and APIs (including LLM APIs like GPT-4o or Claude) introduce governance challenges because the third-party organisation controls the underlying model, including when it changes. Your organisation’s model governance framework must cover third-party models used in regulated contexts: you need contractual guarantees about model stability and change notification, you need to validate the model’s behaviour for your specific use case (you cannot rely on the vendor’s general claims), and you need to monitor the third-party model’s outputs for drift and quality degradation with the same discipline you would apply to an internally developed model. For high-risk regulated use cases, the regulatory expectation is that you govern the AI system, not just the code you wrote around it.
How does the EU AI Act affect MLOps obligations in 2025 and beyond? The EU AI Act’s high-risk provisions (Annex III) came into force in August 2024 with a phased compliance timeline. From August 2026, deployers of high-risk AI systems in the EU must implement technical and governance measures including: conformity assessments, technical documentation packages equivalent to a model card plus full governance trail, human oversight mechanisms, and post-market monitoring with incident reporting to national market surveillance authorities. For organisations already operating under SR 11-7 or 21 CFR Part 11, the incremental obligation is primarily documentation alignment and the addition of a formal conformity assessment process. For organisations new to regulated MLOps, the EU AI Act provides a useful forcing function for implementing the practices in this guide.
Conclusion: Regulated MLOps Is a Discipline, Not a Checklist
The organisations that operate ML systems successfully in regulated environments over the long term are not the ones that passed their first audit. They are the ones that built MLOps as a discipline — reproducibility, explainability, independent validation, continuous monitoring, governed change management — into their engineering culture and their organisational structure.
The practices covered in this guide are not the minimum required to pass an audit. They are the practices required to operate ML systems responsibly in environments where the consequences of failure are significant and the obligation to demonstrate accountability is ongoing.
Getting these practices right from the start of a regulated ML programme is significantly more efficient than retrofitting them onto systems that were built without governance in mind. Every model deployed without a reproducible training pipeline, without explainability documentation, without independent validation, and without monitoring becomes technical debt that accumulates against the compliance posture of the programme.Moweb’s Machine Learning & MLOps practice implements regulated MLOps frameworks for financial services, healthcare, and enterprise clients across the UK, USA, Australia, and India. Our AI Security & Governance practice handles the compliance documentation and regulatory alignment layer. If your organisation is building a regulated ML programme or auditing an existing one, talk to our team about where to start.
Found this post insightful? Don’t forget to share it with your network!