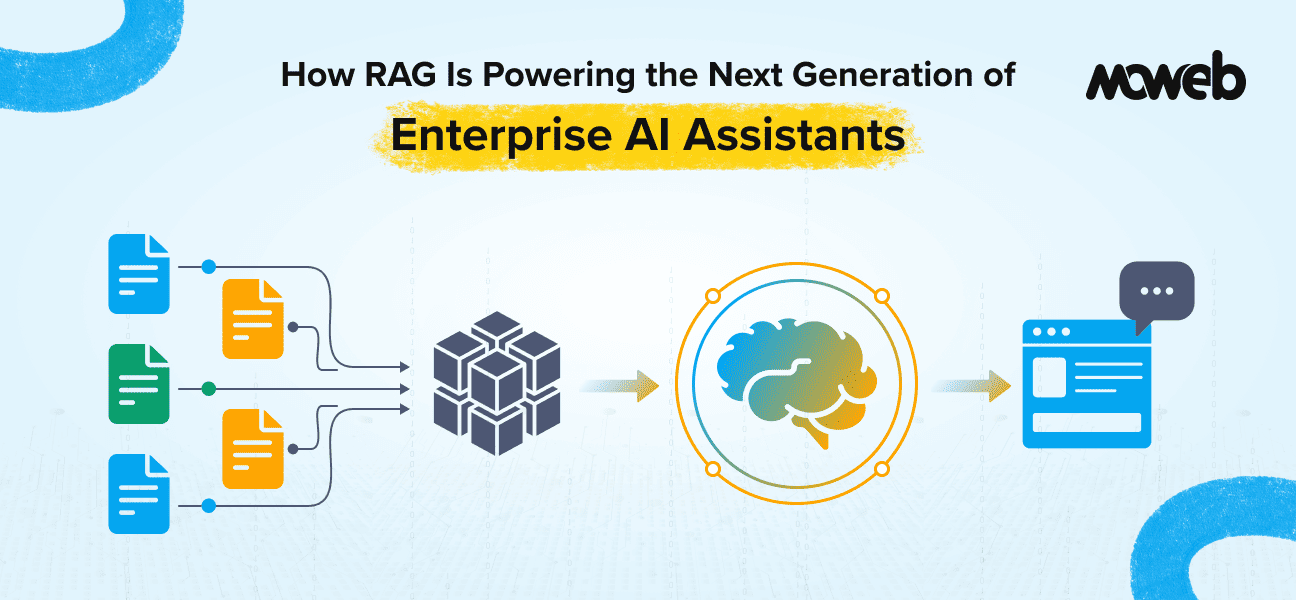
Enterprise AI assistants are evolving from simple chat interfaces into operational intelligence systems. Organizations are deploying AI copilots to support finance teams, automate compliance workflows, enhance customer service, and improve internal knowledge access.
However, most generative AI implementations struggle inside real enterprise environments. They lack access to live internal systems, produce hallucinated outputs, and introduce governance risks.
Retrieval-Augmented Generation (RAG) is emerging as the architectural foundation that enables secure, scalable, and production-ready enterprise AI assistants.
This guide explains how RAG works, why it matters for enterprise AI, what production architecture looks like, and how organizations can implement it effectively.
AI Overview Summary (Optimized for Search & AI Engines)
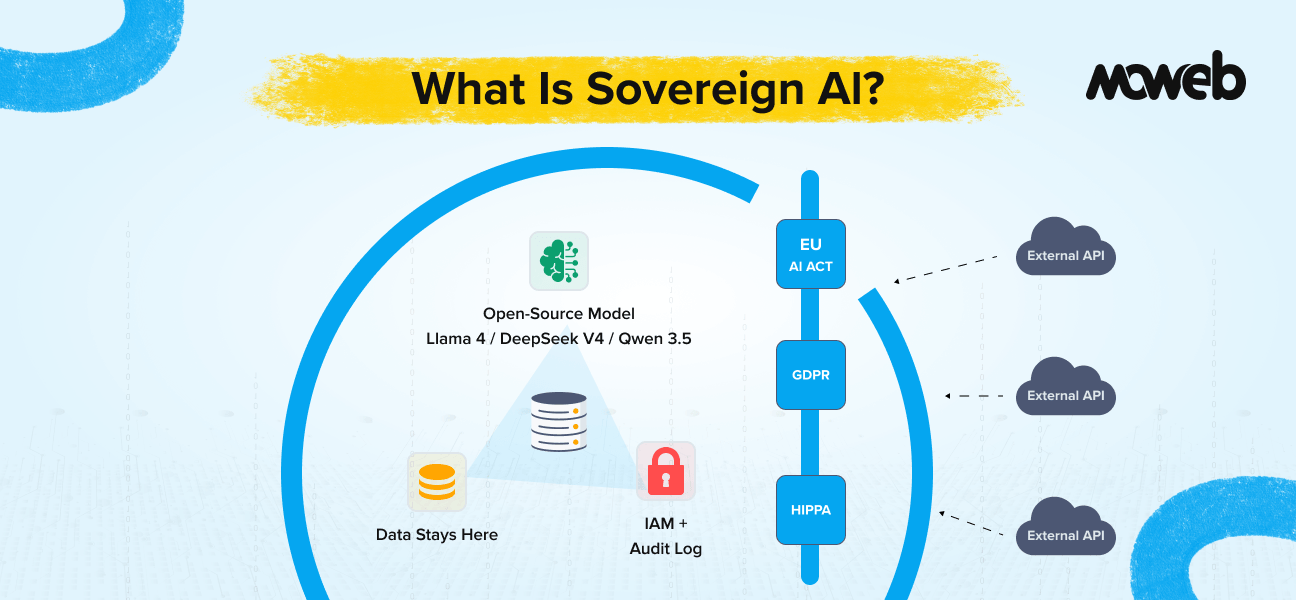
Retrieval-Augmented Generation (RAG) is an enterprise AI architecture that enhances large language models by retrieving relevant data from trusted internal sources before generating responses. By grounding AI outputs in real-time enterprise knowledge such as ERP, CRM, compliance systems, and document repositories, RAG reduces hallucinations, improves factual accuracy, and enables secure AI assistant deployment at scale. RAG is the core technology powering next-generation enterprise AI assistants and AI copilots.
Enterprises adopting AI-driven digital transformation strategies must ensure their assistants operate on trusted internal data.
Why Enterprise AI Assistants Need RAG
Most AI assistants built directly on large language models rely on static training data. That data does not reflect an organization’s internal policies, documents, transactions, or workflows.
Enterprise environments require:
- Access to proprietary systems
- Real-time updates
- Role-based access control
- Auditability
- Compliance safeguards
Without grounding, AI assistants remain experimental tools rather than operational assets.
Organizations exploring AI transformation strategies often start by understanding broader trends in AI adoption. You can explore how AI is reshaping industries in our guide on How AI is Driving Digital Transformation Across Industries.
What Is Retrieval-Augmented Generation in Enterprise AI?
Retrieval-Augmented Generation is an architecture that connects large language models to curated enterprise knowledge sources at query time.
Instead of answering from pre-trained memory alone, the AI assistant:
- Receives a user query
- Retrieves relevant documents from enterprise systems
- Injects that content into the model prompt
- Generates a response grounded in retrieved data
This transforms AI assistants from general-purpose language models into domain-aware enterprise copilots.
Core Components of an Enterprise RAG System
| Component | Role in Enterprise AI |
| Data ingestion pipeline | Extracts and preprocesses structured and unstructured data |
| Embedding engine | Converts documents into vector representations |
| Vector database | Enables semantic search across enterprise knowledge |
| Hybrid retrieval layer | Combines keyword and semantic retrieval |
| Prompt orchestration layer | Injects context into LLM |
| Language model | Generates contextual responses |
| Monitoring & evaluation | Tracks performance and hallucination rates |
RAG often integrates with broader AI and ML pipelines. If you’re exploring implementation strategies, our AI and ML Development Services page outlines how enterprise-grade systems are built end to end.
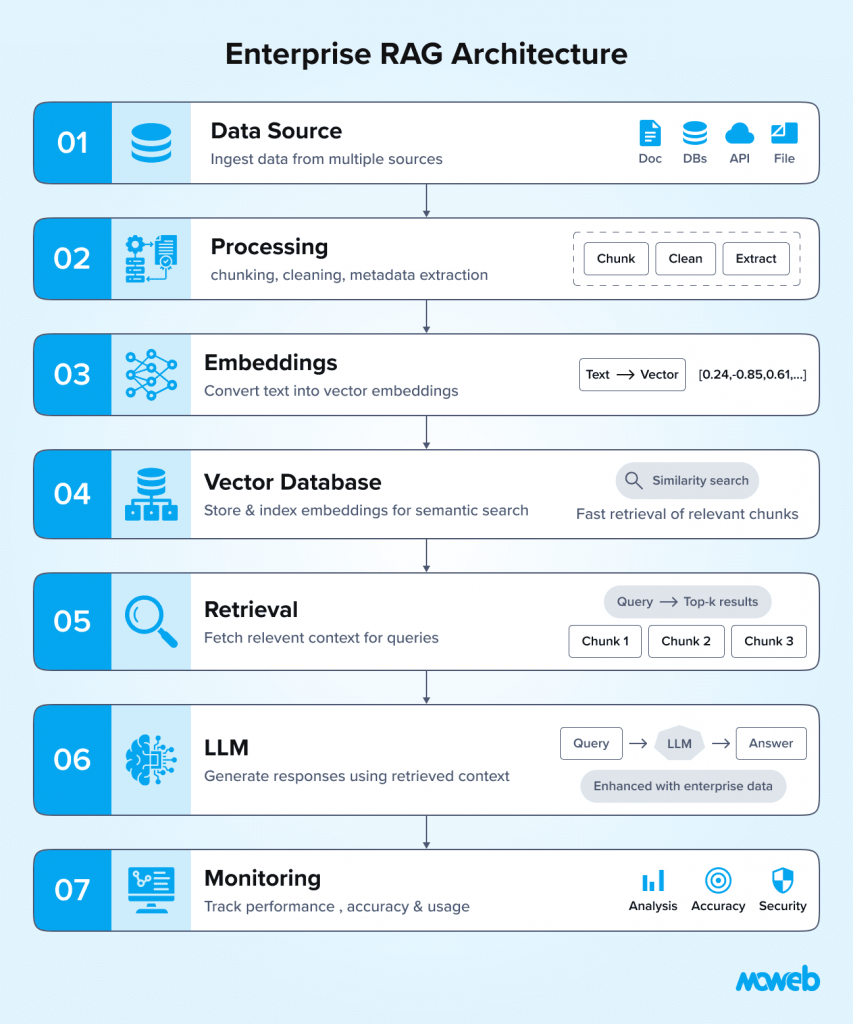
Vector Databases: The Retrieval Engine Behind Enterprise RAG
Retrieval-Augmented Generation systems rely on semantic search to locate the most relevant information inside enterprise knowledge bases. Traditional keyword search struggles to understand intent, synonyms, and contextual meaning.
Vector databases solve this challenge by enabling similarity-based retrieval using embeddings.
What Are Vector Databases?
Vector databases are specialized data storage systems designed to store and retrieve vector embeddings. These embeddings are numerical representations of text, images, or other data generated by machine learning models.
When a document is converted into embeddings, it is represented as a multi-dimensional vector that captures semantic meaning. Instead of matching keywords, vector databases compare vectors to identify the most contextually relevant information.
In a RAG pipeline, this allows AI assistants to retrieve passages that are conceptually similar to the user’s query, even if the wording is different.
Why Vector Databases Are Essential for Semantic Search in RAG
Enterprise AI assistants must retrieve information from:
- Internal Documentation
- Knowledge Bases
- Contracts
- Technical manuals
- Product catalogs
- CRM Records
- Compliance Policies
Traditional search systems rely on keyword matching, which often fails when users phrase queries differently.
Vector databases enable semantic search, which means the system retrieves information based on meaning rather than exact text.
For example:
Query: “Explain the company reimbursement policy for travel expenses.”Semantic retrieval can match documents containing phrases like:
- Employee expense reimbursement
- Travel claim guidelines
- Corporate travel policy
even when those exact words are not present.
This significantly improves retrieval accuracy and user experience in enterprise AI assistants.
How Embeddings Are Stored and Retrieved
In a RAG pipeline, documents first go through an embedding model such as OpenAI embeddings, Sentence Transformers, or other transformer-based models.
The process works as follows:
1️⃣ Enterprise documents are processed and converted into embeddings
2️⃣ These embeddings are stored in a vector database
3️⃣ When a user submits a query, the query is converted into an embedding
4️⃣ The database finds vectors that are most similar to the query vector
5️⃣ Retrieved passages are sent to the language model to generate the final response
This approach ensures responses are grounded in relevant enterprise data rather than model hallucination.
Approximate Nearest Neighbor (ANN) Search
Vector similarity search across millions of documents can be computationally expensive. To enable fast retrieval at scale, most vector databases use Approximate Nearest Neighbor (ANN) algorithms.
ANN search identifies vectors that are very close matches without comparing every vector in the database.
Benefits of ANN search include:
- Dramatically faster query performance
- Scalable retrieval across large datasets
- Real-time response for AI assistants
- Reduced computational overhead
Common ANN techniques include:
- HNSW (Hierarchical Navigable Small Worlds)
- IVF (Inverted File Index)
- Product Quantization
These algorithms allow RAG systems to retrieve relevant information in milliseconds even from millions of stored embeddings.
Metadata Filtering for Enterprise Governance
Enterprise environments require strict governance and access control. Vector databases support metadata filtering, allowing retrieval queries to respect organizational policies.
Examples include:
- Restricting retrieval to specific departments
- Filtering documents by access level
- Retrieving only recent versions of documents
- Isolating data by region or compliance requirement
For example, an AI assistant for HR should not retrieve finance or legal documents unless explicitly authorized.
Metadata filtering ensures that RAG systems operate within enterprise security boundaries.
Financial institutions are already deploying AI agents in financial services to strengthen fraud detection and compliance workflows.
Scalability for Large Enterprise Knowledge Bases
Large enterprises often manage millions of documents across multiple systems such as:
- SharePoint
- ERP platforms
- Internal knowledge bases
- CRM records
- Cloud document storage
Vector databases are designed to scale horizontally and efficiently manage large embedding collections.
They support:
- Distributed indexing
- Incremental updates
- Hybrid search combining vectors and keywords
- High-throughput retrieval
This scalability is essential for enterprise-grade AI assistants that must operate across massive data ecosystems.
Examples of Common Vector Databases
Several vector databases are widely used for enterprise RAG deployments:
| Vector Database | Key Strength |
| Pinecone | Fully managed cloud vector database optimized for production AI workloads |
| Weaviate | Open-source vector database with built-in hybrid search capabilities |
| Milvus | Highly scalable open-source vector database for large datasets |
| Qdrant | High-performance vector search engine designed for modern AI applications |
| Elasticsearch | Supports vector search alongside traditional keyword search |
| pgvector | PostgreSQL extension enabling vector search within relational databases |
The choice of vector database depends on factors such as scale, infrastructure preferences, governance requirements, and integration with existing enterprise systems.
Why Traditional LLM-Based Assistants Fail in Enterprise Settings
1. Static Knowledge
LLMs cannot access live ERP transactions or updated compliance policies.
2. Hallucinations
Models may generate confident but inaccurate responses.
3. Lack of Governance
Without retrieval filters, AI systems may expose sensitive data.
4. No Context Awareness
Generic AI cannot understand organizational roles, departments, or workflow constraints.
RAG addresses these limitations directly.
RAG vs Fine-Tuning: Enterprise Perspective
Fine-tuning modifies internal model parameters using additional training data.
RAG retrieves external knowledge dynamically without altering model weights.
| Decision Factor | RAG | Fine-Tuning |
| Real-time data | Yes | No |
| Governance control | High | Medium |
| Scalability | High | Limited |
| Cost efficiency | Higher long-term | Expensive retraining |
| Use case | Knowledge-intensive workflows | Behavioral specialization |
Most enterprise systems combine RAG with lightweight fine-tuning for tone or format control.
Real Enterprise Use Cases of RAG-Powered AI Assistants
Finance & Compliance Assistants
- Retrieve policy documents
- Explain regulatory rules
- Support internal audit queries
Organizations leveraging AI in financial environments often expand into fraud detection and automation. For related insights, see How AI Agents Help Fraud Detection in Financial Services.
Customer Support Copilots
RAG-powered assistants retrieve:
- Product manuals
- Past support cases
- Knowledge base articles
This reduces resolution time and improves consistency.
You can also explore AI-driven customer experience optimization in our guide on Deploying AI for Predictive Analytics in E-Commerce Platforms.
HR and Internal Knowledge Assistants
- Provide onboarding guidance
- Retrieve HR policies
- Support training queries
AI assistants enhance operational efficiency by eliminating manual document searches.
Supply Chain Decision Support
- Retrieve vendor contracts
- Analyze inventory records
- Compare logistics data
AI is rapidly transforming logistics and inventory management. Learn more in How AI Is Transforming Supply Chain Management.
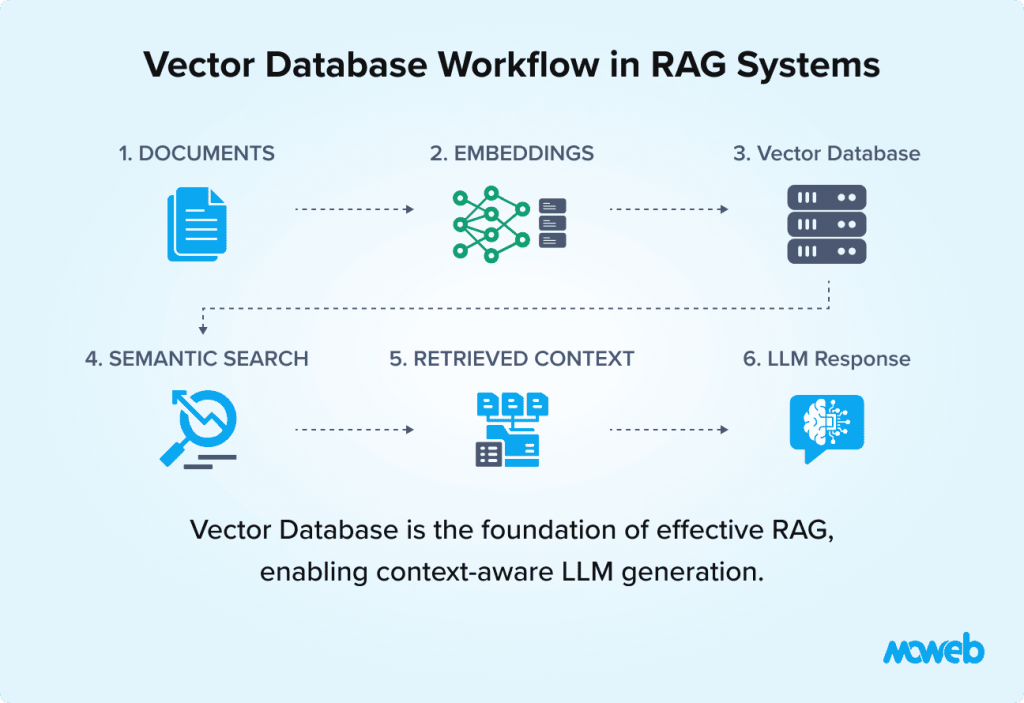
Advanced RAG Techniques for Enterprise AI Assistants
Enterprise-grade implementations extend beyond basic vector search.
Hybrid Retrieval
Combines semantic and keyword search for higher precision.
Multi-Stage Retrieval
Initial filtering followed by passage reranking improves contextual accuracy.
Graph RAG
Integrates knowledge graphs to enable multi-hop reasoning across complex entity relationships.
Agentic RAG
Allows AI assistants to:
- Break down complex queries
- Execute multi-step retrieval
- Trigger system workflows
If you’re exploring intelligent agents further, see our blog on How to Implement Agentic AI in Your Business.
Many organizations are extending RAG with autonomous agents capable of multi-step reasoning and workflow execution.
PageIndex / Page-Level Indexing: Improving Retrieval Accuracy in RAG
One of the most common mistakes in RAG implementation is indexing entire documents as single embeddings.
While this approach is simple, it significantly reduces retrieval precision and increases token usage during generation.
Page-level indexing, often referred to as PageIndex or passage indexing, solves this problem by breaking documents into smaller chunks before embedding them.
Why Indexing Entire Documents Reduces Retrieval Accuracy
Enterprise documents such as:
- Contracts
- Technical manuals
- Training guides
- Research papers
- Compliance documents
can contain dozens or even hundreds of pages.
When an entire document is converted into a single embedding, the vector represents the overall meaning of the document, not specific sections.
As a result, retrieval systems may return documents that are broadly related but do not contain the precise information needed.
This leads to:
- Less accurate responses
- Higher token usage in prompts
- Slower response generation
How PageIndex Breaks Documents into Smaller Passages
PageIndex solves this problem by dividing documents into pages, sections, or passages before generating embeddings.
Each chunk is embedded separately and stored in the vector database.
A typical pipeline works like this:
1️⃣ Documents are parsed into pages or text chunks
2️⃣ Each chunk is converted into an embedding
3️⃣ Metadata such as page number and document title is stored
4️⃣ Queries retrieve the most relevant passages rather than entire documents
5️⃣ Retrieved passages are injected into the prompt for the language model
This granular indexing approach significantly improves retrieval quality.
Benefits of Page-Level Indexing in Enterprise RAG Systems
Higher Retrieval Precision
Chunked indexing ensures that AI assistants retrieve specific sections that answer the user’s question rather than entire documents.
This improves factual accuracy.
Lower Token Usage
When entire documents are injected into prompts, token consumption increases rapidly.
PageIndex retrieves only relevant passages, reducing token costs and improving response speed.
Better Citations
Page-level indexing allows AI assistants to reference specific page numbers or document sections.
This improves transparency and user trust.
Example:
“According to page 12 of the policy document…”
Improved Auditability
Enterprises often require traceable AI outputs.
Page-level indexing ensures responses can be traced back to exact source passages.
This supports:
- Compliance audits
- Regulatory reviews
- Enterprise governance policies
Faster Retrieval
Smaller indexed chunks improve the efficiency of vector similarity searches.
The system can quickly identify the most relevant passages instead of processing entire documents.
Security and Governance in Enterprise RAG Systems
Enterprise AI must comply with regulatory and operational standards.
Governance Controls Include:
- Role-based document retrieval
- Encryption at rest and transit
- Audit logging of retrieval events
- Output validation pipelines
- Prompt injection safeguards
Security-first architecture is essential in industries such as healthcare, fintech, and manufacturing.
Building a secure RAG architecture requires strong enterprise data engineering pipelines to process structured and unstructured knowledge sources.
Measuring Enterprise AI Assistant Success
Enterprises must track performance metrics.
| KPI | Purpose |
| Retrieval accuracy | Ensures relevant context |
| Hallucination rate | Measures reliability |
| Query latency | Impacts usability |
| Adoption rate | Indicates organizational trust |
| Time saved | Quantifies productivity impact |
| Cost reduction | Measures ROI |
Continuous evaluation and retriever optimization are critical for long-term performance.
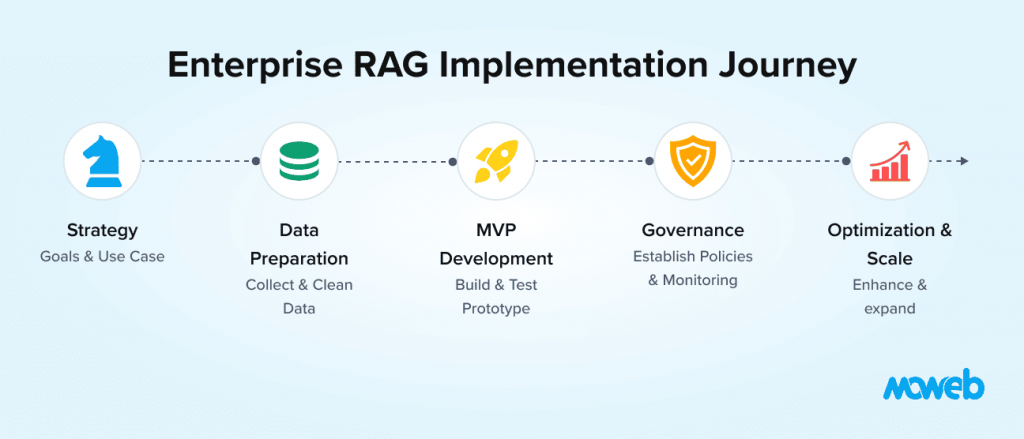
Implementation Roadmap for Enterprise RAG
Phase 1 – Identify High-Impact Use Case
Select a knowledge-intensive workflow.
Phase 2 – Data Audit
Assess document quality, access levels, and classification.
Phase 3 – Deploy MVP RAG Pipeline
Embed documents, configure retrieval, integrate LLM.
Phase 4 – Add Governance Controls
Implement access policies and monitoring.
Phase 5 – Optimize & Scale
Introduce hybrid retrieval, reranking, and agentic orchestration.
Organizations seeking a complete AI transformation strategy often align RAG initiatives with broader enterprise modernization efforts, such as those covered under our Enterprise Software Development Services.
Successful deployment often requires enterprise software engineering expertise to integrate AI systems with ERP, CRM, and internal platforms.
The Future of Enterprise AI Assistants
RAG is evolving into the intelligence backbone for:
- AI copilots integrated into ERP and CRM
- Autonomous enterprise agents
- Workflow automation systems
- Multimodal AI assistants
- Real-time executive dashboards
As AI assistants become more autonomous, retrieval grounding will remain the verification layer that ensures reliability and compliance.
Why Enterprise-Grade RAG Requires Engineering Expertise
Implementing RAG is not about connecting a chatbot API to a vector database.
It requires:
- Data engineering
- DevOps automation
- Secure system integration
- Evaluation frameworks
- Monitoring pipelines
- Compliance architecture
Without disciplined engineering, enterprise AI assistants introduce more risk than value.
Frequently Asked Questions
1. How is RAG different from simply uploading documents into ChatGPT or a similar consumer AI tool?
Consumer AI tools that accept document uploads process those documents within a single session context window meaning the documents are temporarily loaded into the prompt, not indexed for persistent retrieval. Enterprise RAG maintains a permanently indexed, continuously updated knowledge base that persists across every session, scales to millions of documents, enforces access control per user and role, and logs every retrieval event for audit purposes. The difference isn’t cosmetic, it’s the difference between a demo and a production system.
2. How do you prevent sensitive information from leaking between departments through a shared RAG system?
This is handled at the metadata and retrieval filter layer. Every document ingested into the system is tagged with access classification metadata department, clearance level, data sensitivity category, regional scope. When a query comes in, the retrieval layer applies filters based on the authenticated user’s role and permissions before returning any results. A finance document never enters the retrieval candidate set for an HR query. The security boundary is enforced before the language model ever sees the content, not after.
3. What’s the risk of RAG retrieving outdated documents if the knowledge base isn’t properly maintained?
It’s a real and underappreciated risk. RAG is only as current as its indexed content. If a policy document is updated but the old version remains in the vector database without being replaced or deprecated, the system may confidently retrieve and cite the outdated version. Mitigating this requires automated re-ingestion pipelines triggered by source document updates, versioning metadata that allows retrieval to prefer the latest version, and periodic knowledge base audits. Data maintenance is an operational discipline, not a one-time setup task.
4. Can RAG systems understand and retrieve information from tables, charts, and non-text content inside documents?
Standard text-based RAG pipelines struggle with structured content like tables, charts, and embedded images because embedding models are trained primarily on prose. Specialized approaches address this: table-aware chunking that preserves row and column relationships during ingestion, multimodal embedding models that can encode both text and visual content, and document parsing tools that convert tables into structured text representations before embedding. For enterprises whose critical knowledge lives in spreadsheets, financial reports, or technical diagrams, this is an important architectural consideration that should be scoped early.
5. At what point does a RAG system become too complex to manage internally, and when should an organization bring in outside expertise?
The inflection point is usually when the system moves beyond a single use case and a single document source. A scoped MVP, one knowledge base, one user group, one query type is manageable for an internal team with solid data engineering capability. Complexity compounds quickly when you add multiple retrieval sources with different formats, role-based access control across organizational hierarchies, agentic workflows that trigger downstream actions, multilingual content, and compliance requirements that demand formal audit trails. At that stage, the engineering surface area spans data pipelines, vector infrastructure, LLM orchestration, security architecture, and evaluation frameworks simultaneously and the cost of getting any one layer wrong in a regulated environment is high enough that outside expertise typically pays for itself.
6. How is RAG different from simply uploading documents into ChatGPT or a similar consumer AI tool?
Consumer AI tools that accept document uploads process those documents within a single session context window meaning the documents are temporarily loaded into the prompt, not indexed for persistent retrieval. Enterprise RAG maintains a permanently indexed, continuously updated knowledge base that persists across every session, scales to millions of documents, enforces access control per user and role, and logs every retrieval event for audit purposes. The difference isn’t cosmetic, it’s the difference between a demo and a production system.
7. How do you prevent sensitive information from leaking between departments through a shared RAG system?
This is handled at the metadata and retrieval filter layer. Every document ingested into the system is tagged with access classification metadata department, clearance level, data sensitivity category, regional scope. When a query comes in, the retrieval layer applies filters based on the authenticated user’s role and permissions before returning any results. A finance document never enters the retrieval candidate set for an HR query. The security boundary is enforced before the language model ever sees the content, not after.
8. What’s the risk of RAG retrieving outdated documents if the knowledge base isn’t properly maintained?
It’s a real and underappreciated risk. RAG is only as current as its indexed content. If a policy document is updated but the old version remains in the vector database without being replaced or deprecated, the system may confidently retrieve and cite the outdated version. Mitigating this requires automated re-ingestion pipelines triggered by source document updates, versioning metadata that allows retrieval to prefer the latest version, and periodic knowledge base audits. Data maintenance is an operational discipline, not a one-time setup task.
9. Can RAG systems understand and retrieve information from tables, charts, and non-text content inside documents?
Standard text-based RAG pipelines struggle with structured content like tables, charts, and embedded images because embedding models are trained primarily on prose. Specialized approaches address this: table-aware chunking that preserves row and column relationships during ingestion, multimodal embedding models that can encode both text and visual content, and document parsing tools that convert tables into structured text representations before embedding. For enterprises whose critical knowledge lives in spreadsheets, financial reports, or technical diagrams, this is an important architectural consideration that should be scoped early.
10. At what point does a RAG system become too complex to manage internally, and when should an organization bring in outside expertise?
The inflection point is usually when the system moves beyond a single use case and a single document source. A scoped MVP one knowledge base, one user group, one query type is manageable for an internal team with solid data engineering capability. Complexity compounds quickly when you add multiple retrieval sources with different formats, role-based access control across organizational hierarchies, agentic workflows that trigger downstream actions, multilingual content, and compliance requirements that demand formal audit trails. At that stage, the engineering surface area spans data pipelines, vector infrastructure, LLM orchestration, security architecture, and evaluation frameworks simultaneously and the cost of getting any one layer wrong in a regulated environment is high enough that outside expertise typically pays for itself.
🚀 Build Secure, Scalable Enterprise AI Assistants with Moweb
Deploying RAG-based enterprise AI assistants demands more than experimentation. It requires production-grade architecture, system integration expertise, and governance-first design.
At Moweb, we help organizations:
- Design secure RAG architectures
- Integrate AI with ERP, CRM, and enterprise platforms
- Implement vector search and hybrid retrieval
- Build agentic AI workflows
- Ensure regulatory compliance and data security
From strategy and architecture to deployment and optimization, our team enables enterprises to transform fragmented knowledge into intelligent, actionable AI systems.
Explore our enterprise AI development services to build production-ready RAG systems.
The next generation of enterprise AI assistants is grounded, secure, and architected for scale. RAG is the foundation. Execution is the differentiator.
Found this post insightful? Don’t forget to share it with your network!