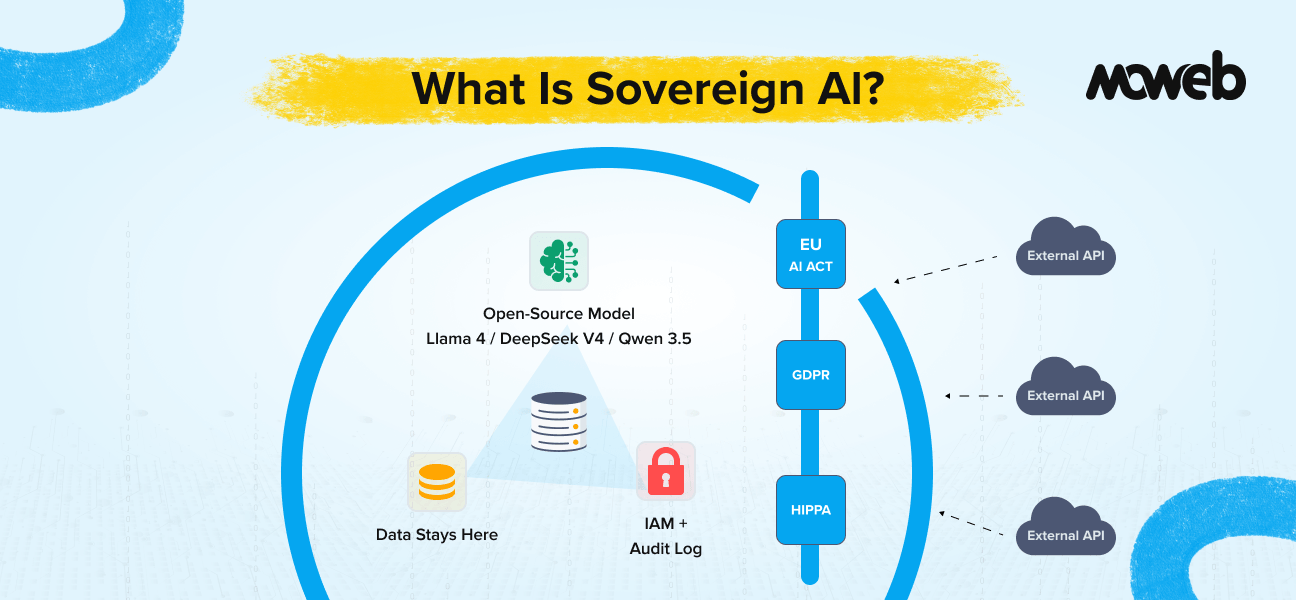
What is sovereign AI? Sovereign AI refers to the strategy of deploying, operating, and governing AI systems within an organisation’s own infrastructure – or within a jurisdiction-specific cloud – rather than routing data and inference through third-party AI APIs hosted in other countries or by external corporations. A sovereign AI strategy gives the organisation full control over which data the AI can access, where that data is processed and stored, which model is used and how it is updated, and who can audit or inspect the system’s behaviour. It is the AI equivalent of running your own data centre rather than relying entirely on public cloud infrastructure – chosen when the compliance, security, or competitive sensitivity of the data makes external processing unacceptable.
Why are enterprises moving to on-premises AI model deployment in 2026? Three pressures are converging. First, regulatory tightening: the EU AI Act’s binding enforcement date for high-risk AI systems is 2 August 2026 (Articles 9–17 and Article 26), and expanded GDPR enforcement and sector-specific data localisation laws in financial services and healthcare are making it legally risky to process sensitive data through foreign AI APIs in many jurisdictions. Second, geopolitical risk: reliance on US-based AI infrastructure has become a boardroom-level concern for European, Asian, and emerging market enterprises following successive executive orders and export control expansions. Third, capability maturity: open-source models in 2026 ( Llama 4, Mistral Large 3, Qwen 3.5, and DeepSeek V4) have reached performance levels that make on-premises deployment viable for most enterprise use cases, removing the capability trade-off that made API dependency seem unavoidable two years ago.
Two years ago, the default architecture for enterprise AI was cloud API dependency. You wanted an LLM, you called OpenAI or Anthropic via API. Your data left your infrastructure, was processed by a model you did not own, on servers you could not inspect, governed by terms you could not fully audit.
For many organisations, this was an acceptable trade-off. The models were capable. The cost was manageable. The alternative – running your own models – required infrastructure and expertise most enterprises did not have.
That calculus has changed significantly in 2026. The global sovereign AI infrastructure market was valued at $14.8 billion in 2025 and is projected to reach $49.7 billion by 2033 (Data Bridge Market Research, 2026), with more aggressive estimates from NMSC putting 2026 value already at $78 billion. McKinsey’s December 2025 analysis estimated sovereign AI could become a $600 billion total opportunity by 2030. On-premises deployments commanded the largest market share in 2025, with the hybrid segment projected to grow fastest at a 17.2% CAGR through 2033. Accenture reports that 61% of business leaders are more likely to seek sovereign technology solutions as geopolitical risks rise.
This is not a niche concern for government agencies. It is a mainstream enterprise technology strategy, accelerating across financial services, healthcare, manufacturing, legal services, and any organisation that handles sensitive data at scale.
This guide explains what sovereign AI means in practice, why the shift is happening now, which open-source models make on-premises deployment viable, and how to design a sovereign AI architecture that meets both capability and compliance requirements.
What Sovereign AI Actually Means?
Sovereign AI is an umbrella term with several related but distinct meanings depending on context. Understanding which meaning applies to your organisation is the first step in building a coherent strategy.
National sovereign AI refers to countries building their own AI infrastructure, models, and data governance frameworks to reduce dependence on foreign AI technology. France’s Mistral, UAE’s Falcon, India’s Sarvam, and the EU’s broader investment in AI infrastructure all fall into this category. This is the definition that appears most often in geopolitical and policy discussions.
Enterprise sovereign AI is the application of the same principle at the organisational level: an enterprise deploying, operating, and governing AI systems within infrastructure it controls, under data governance it owns, with the ability to audit and modify the system without dependency on a third-party vendor’s decisions or terms.
Data sovereignty is the narrower concept that enterprise AI strategies most frequently start from: the requirement that data be processed and stored within a specific geographic jurisdiction or organisational boundary, regardless of which AI model processes it.
For this guide, sovereign AI means the enterprise version: the strategy of deploying AI in environments where the organisation retains full control over data, models, infrastructure, and governance.
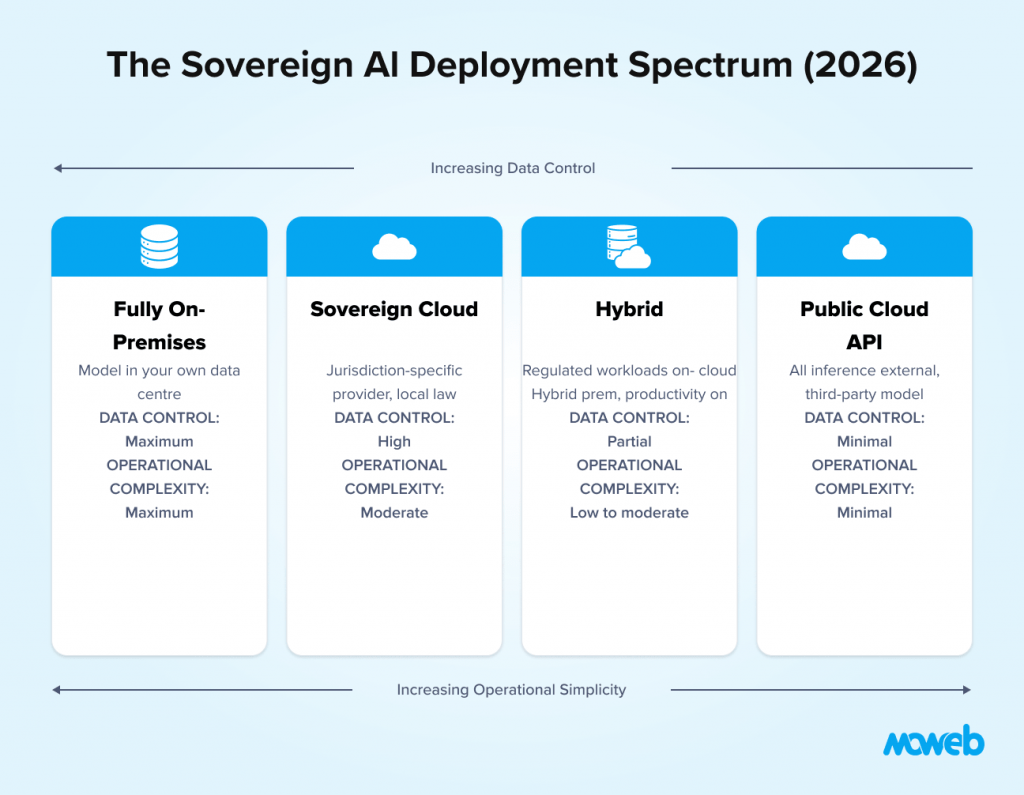
A sovereign AI architecture is not necessarily fully on-premises. It exists on a spectrum:
- Fully on-premises: Model runs entirely within the organisation’s own data centre or private cloud. Maximum control, maximum infrastructure investment.
- Sovereign cloud: Model runs within a cloud environment operated by a provider in the same legal jurisdiction, under local data protection law, with contractual guarantees about data residency and access. Balance of control and operational convenience.
- Hybrid: Sensitive data and regulated workloads run on-premises or sovereign cloud. Lower-sensitivity productivity workloads use public cloud AI APIs. Most practical architecture for large enterprises with varied data classifications.
- Public cloud API: All inference is routed through an external API. Maximum convenience, minimum control. Appropriate for non-sensitive use cases.
A sovereign AI strategy does not require every workload to stay on-premises. It requires the ability to run AI in the environment that best fits the use case, the data, and the regulatory context.
Why the Shift Is Happening Now: Four Converging Pressures
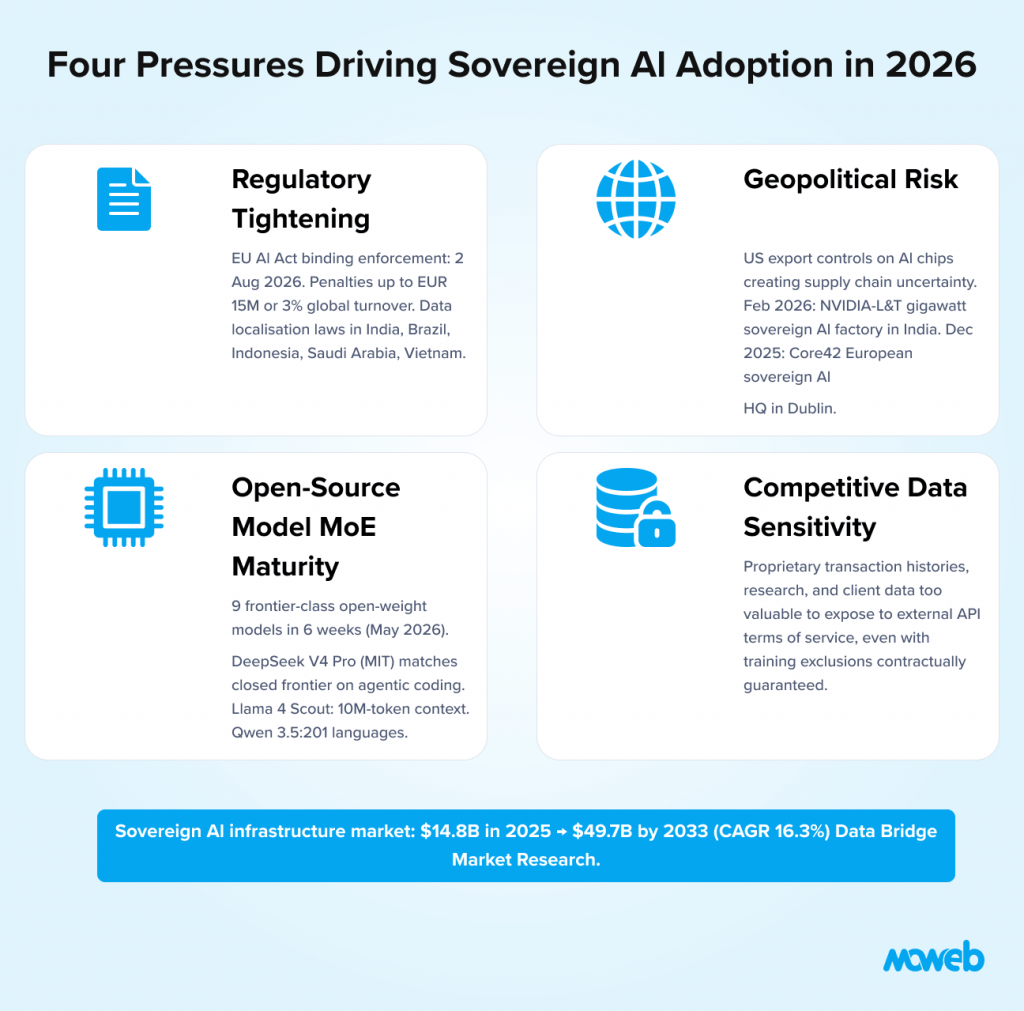
The movement toward sovereign AI in 2026 is not driven by a single factor. Four pressures are converging simultaneously, and their combined effect is why the strategy has moved from theoretical to boardroom-level in the past 18 months.
Pressure 1: Regulatory Tightening on Data Localisation
The EU AI Act’s binding enforcement date for high-risk AI systems is 2 August 2026, covering Articles 9–17 (provider requirements) and Article 26 (deployer requirements) with penalties of up to EUR 15 million or 3% of global annual turnover for non-compliance. Despite a November 2025 European Commission proposal to delay certain deadlines to late 2027, this extension has not been enacted into law, and enterprises should treat August 2026 as the operative deadline. High-risk AI systems covering credit, employment, healthcare, education, and critical infrastructure must maintain technical documentation, event logs, and the ability to demonstrate compliance to regulators. These requirements are difficult to satisfy when the AI system is a third-party API whose internals are not accessible to the deploying organisation.
Beyond the EU AI Act, data localisation requirements have expanded significantly. India’s Digital Personal Data Protection Act restricts cross-border transfer of certain personal data. Brazil’s LGPD, Indonesia’s PDP Law, Saudi Arabia’s PDPL, and Vietnam’s Cybersecurity Law all create data residency requirements that processing data through US-hosted AI APIs may violate without appropriate data processing agreements and technical safeguards.
For financial institutions in the UK operating under FCA guidance, for healthcare organisations in the US managing PHI under HIPAA, and for any organisation processing EU personal data under GDPR, the legal due diligence burden of external AI API usage has increased substantially. Sovereign AI deployment sidesteps many of these compliance questions by keeping data within the jurisdiction and infrastructure where it was collected.
Pressure 2: Geopolitical Risk and Supply Chain Uncertainty
US executive orders expanding AI export controls and restricting access to advanced AI chips have created genuine supply chain uncertainty for non-US enterprises. For European, Asian, and emerging market organisations, the risk of future access restrictions to US-hosted AI services is no longer theoretical – it is a board-level risk management question.
The organisations most exposed to this risk are those that have built critical operational processes on top of AI services they do not own or control. A bank that routes customer credit assessments through an external AI API does not have a reliable business process – it has a business process that depends on the continued availability of a service it cannot guarantee. Sovereign AI deployment converts that dependency into owned infrastructure. A concrete signal of this pressure: in February 2026, NVIDIA partnered with Larsen & Toubro to build a gigawatt-scale sovereign AI factory under India’s AI Mission, and in December 2025 Core42 established its European headquarters in Dublin specifically to serve rising demand for sovereign AI infrastructure across the region.
Pressure 3: Open-Source Model Maturity
The capability argument against on-premises AI has weakened substantially in 2026. The performance gap between proprietary frontier models and open-source alternatives has narrowed considerably on enterprise-relevant benchmarks. As of May 2026, nine frontier-class open-weight models shipped in roughly six weeks Kimi K2.6, DeepSeek V4 Pro, DeepSeek V4 Flash, MiniMax-M2.7, Gemma 4, Qwen 3.6, GLM-5.1, Mistral Large 3, and Ring-2.6 representing the fastest acceleration in open-source model capability in the field’s history.
Meta’s Llama 4 Scout (17B active parameters, 10M-token context window, MoE architecture) and Maverick (17B active, 400B total, highest MMLU at 85.5% among open models) are the most widely deployed open-source models in enterprise settings and are deployable under the Meta custom licence (with a 700M MAU usage cap; review before enterprise deployment). DeepSeek V4 Pro (MIT licence, 49B active parameters, 1.6T total) leads the neutral Artificial Analysis Intelligence Index at 52, ranking first for agentic coding among open-weight models and carries a fully permissive MIT licence with no geographic restrictions. Alibaba’s Qwen 3.5 and Qwen 3.6 (Apache 2.0) excel on reasoning and multilingual tasks across 201 languages, with Qwen 3.6 scoring 77.2 on SWE-Bench Verified. Mistral Large 3 (Apache 2.0, 80+ languages) remains the strongest choice for European enterprise deployment given the French company’s EU data governance alignment, though it scores below DeepSeek and Qwen tiers on independent benchmarks as of May 2026. Cohere Command R+ remains the leading choice for RAG-specific deployments.
These models can be deployed on-premises using inference frameworks including vLLM, Ollama, LM Studio, and NVIDIA NIM (which provides containerised, enterprise-grade model serving for NVIDIA GPU infrastructure). The hardware investment is meaningful but has dropped significantly as H100 and A100 alternatives have entered the market and as newer MoE model architectures require less compute per inference request than equivalent-capability dense models. A practical benchmark: Qwen 3.5 397B-A17B runs at over 5.5 tokens per second on a MacBook Pro M4 Max, illustrating how far inference efficiency has advanced beyond data centre-only deployment
Pressure 4: Competitive Sensitivity of Proprietary Data
The fourth pressure is less about regulation and more about competitive strategy. Enterprises with genuinely proprietary data assets – unique transaction histories, proprietary research, competitive intelligence, confidential client relationships – are increasingly reluctant to expose that data to AI provider terms of service, even when training exclusions are contractually guaranteed.
The logic is straightforward: the value of a competitive intelligence AI assistant trained on your proprietary market data depends on that data remaining exclusive. Processing it through an external API, even under terms that prohibit training, introduces counterparty risk that did not exist before. Sovereign deployment eliminates that risk.
The Open-Source Models Making On-Premises Viable in 2026
Sovereign AI deployment requires a model you can run. Here is the practical landscape of open-source models viable for enterprise on-premises deployment in 2026.
Llama 4 Scout and Maverick (Meta): The most widely deployed open-source model family in enterprise settings. Scout offers a 10M-token context window unmatched among open-weight models, making it the choice for long-document and long-context enterprise workflows. Maverick posts the highest MMLU (85.5%) among open models. Licence: Meta custom; review the 700M monthly active user clause before enterprise deployment, as this may affect very large deployments or platform businesses. Available via Hugging Face, deployable with vLLM, Ollama, or NVIDIA NIM.
DeepSeek V4 Pro (DeepSeek): The strongest open-weight model for agentic coding workflows as of May 2026, leading the neutral Artificial Analysis Intelligence Index at 52 and performing on par with closed frontier models on SWE-Bench. Licence: MIT, the most permissive major open-weight licence, with no geographic restrictions, no usage caps, and no royalty requirements. 1.6T total parameters, 49B active (MoE). 1M-token context window. Enterprise note: DeepSeek is a Chinese company; organisations with data sovereignty requirements related to country of model origin should evaluate whether the MIT licence and self-hosted deployment adequately address those requirements for their specific regulatory context.
Mistral Large 3 and Mistral Small 4: Mistral’s models are particularly strong for European enterprise deployment given the French company’s alignment with EU data governance expectations. Both are now Apache 2.0 licensed, fully permissive. Mistral Small 4 is particularly strong for production agents requiring function calling, JSON output, and reasoning mode, with 6B active parameters suitable for cost-constrained inference. Mistral Large 3 covers 80+ languages. Enterprise note: as of May 2026, Mistral models score below DeepSeek V4 and Qwen 3.5/3.6 tiers on neutral benchmarks; evaluate against your specific use case requirements rather than general leaderboard position.
Qwen 3.5 and Qwen 3.6 (Alibaba): Qwen 3.5 supports 201 languages and leads on multilingual tasks as the strongest open-weight model for enterprises operating across Asian, European, and emerging markets simultaneously. Qwen 3.6-27B scores 77.2 on SWE-Bench Verified (best small dense coder under Apache 2.0). Qwen 3.5 397B-A17B uses MoE architecture, enabling efficient inference despite large total parameter count. Apache 2.0 licence across most variants. Enterprise note: Alibaba is a Chinese company; the same sovereignty evaluation as DeepSeek applies for organisations with country-of-origin requirements.
Gemma 4 (Google): Gemma 4 was released in April 2026 under Apache 2.0, a significant licence improvement from prior Gemma versions. 256K context window. Competitive performance in a smaller parameter envelope than Llama 4 Maverick, making it suitable for deployment on less expensive GPU hardware. Well-documented integration with Google’s toolchain for organisations standardising on GCP infrastructure.
Phi-4 Mini (Microsoft): Microsoft’s small language model family is particularly relevant for edge and embedded deployments where inference cost per token is the primary constraint. Not a frontier model replacement but appropriate for specific high-frequency, lower-complexity enterprise tasks running on constrained hardware.
GLM-5 (Z.ai): MIT-licensed, the cleanest enterprise licence among frontier-class open-weight models. Scores 77.8 on SWE-Bench Verified, making it the leading open model for enterprise agentic engineering. Less widely known in Western enterprise contexts but technically competitive and fully permissive for commercial deployment.
The right model choice for a sovereign deployment depends on your specific use case requirements (language support, context window, coding performance), your available GPU infrastructure, your licensing requirements, and the inference framework your engineering team can operate.
Sovereign AI Architecture: What Enterprise Deployment Actually Looks Like
Building a sovereign AI deployment is not simply a matter of downloading a model and running it on a server. A production enterprise sovereign AI architecture has several components that must be designed together.
Inference infrastructure. GPU-accelerated compute is required for practical LLM inference at enterprise scale. NVIDIA H100 and H200 GPUs are the current standard for high-performance inference. A100 GPUs offer a cost-effective alternative for organisations with moderate throughput requirements. For organisations unwilling to make capital infrastructure investments, bare-metal GPU cloud providers (Coreweave, Lambda Labs, Vultr) offer sovereign-adjacent deployment within a single jurisdiction without the capital expenditure of owned hardware.
Inference serving framework. The model requires a serving layer that handles API routing, batching, concurrency management, and monitoring. vLLM is the most widely adopted open-source inference serving framework for production enterprise deployments, offering PagedAttention for memory efficiency and continuous batching for throughput optimisation. NVIDIA NIM provides an enterprise-supported containerised alternative with NVIDIA’s production support model.
Data pipeline and RAG layer. Most enterprise sovereign AI deployments combine a base model with a RAG system that grounds responses in the organisation’s own documents. The data pipeline ingests, chunks, embeds, and indexes documents into a vector database (Qdrant, Weaviate, or pgvector for simpler deployments). The embedding model must also be deployable on-premises – BGE-M3, E5-Mistral, and Nomic Embed are the leading open-source options. For the full RAG architecture, our guide to RAG development for enterprise knowledge systems covers the complete implementation.
Access control and audit layer. A sovereign deployment is only as sovereign as its access controls. The IAM integration, retrieval-level permission filtering, and audit logging that every enterprise AI system requires – described in our guide to building secure enterprise chatbots with audit trails and compliance – apply with equal force to sovereign on-premises deployments. The difference is that in a sovereign deployment, these controls are entirely within the organisation’s own infrastructure rather than relying on a third-party provider’s security model.
Monitoring and MLOps. On-premises model deployments require the same monitoring infrastructure as cloud-hosted AI: latency tracking (p50, p95, p99), output quality monitoring, drift detection, and model update management. Our guide to MLOps best practices for regulated industries covers this operational layer in detail.
When Sovereign AI Is the Right Choice – and When It Is Not
Sovereign AI deployment is not appropriate for every organisation or every use case. The decision framework comes down to five questions.
Is your data subject to data localisation requirements? If yes, sovereign deployment within the relevant jurisdiction is likely required for compliance regardless of other factors.
Does your use case involve data that would create competitive or regulatory exposure if processed externally? If yes, sovereign deployment eliminates that exposure.
Do you have or can you acquire the GPU infrastructure and engineering capability to operate a production AI system? If no, a sovereign cloud arrangement with a jurisdiction-appropriate provider may deliver equivalent data protection without the operational complexity of fully owned infrastructure.
Does the performance of available open-source models meet your use case requirements? For most enterprise knowledge management, document processing, and code assistance use cases, the answer in 2026 is yes. For agentic coding workflows, DeepSeek V4 Pro now performs on par with closed frontier models. For long-context enterprise applications, Llama 4 Scout’s 10M-token window exceeds what most proprietary APIs offer. For use cases requiring frontier reasoning performance on very complex tasks, proprietary API models retain an advantage on the most demanding benchmarks.
Is your AI use case sensitive enough to justify the infrastructure cost differential? On-premises AI is more expensive to set up and operate than cloud API access. The cost differential is justifiable when the compliance risk, competitive sensitivity, or operational resilience requirements make the sovereignty premium worthwhile.
The enterprises with the clearest sovereign AI business case in 2026 are those in financial services handling customer data under strict data localisation requirements, healthcare organisations processing PHI where BAA limitations with LLM providers create compliance risk, government and defence contractors where data classification requirements preclude external processing, and enterprises in regulated markets where future AI regulation may impose additional requirements on external AI API usage.
Frequently Asked Questions About Sovereign AI
What is the difference between sovereign AI and private cloud AI? Private cloud AI means running AI infrastructure in a cloud environment that is dedicated to your organisation but managed by a cloud provider. Sovereign AI is broader: it encompasses private cloud, on-premises deployment, and any arrangement where the organisation retains control over data residency, model selection, and system governance – regardless of the specific infrastructure model. Private cloud can be a component of a sovereign AI architecture, but sovereign AI is about governance and control rather than a specific deployment model.
Can we achieve data sovereignty using a managed cloud provider like AWS or Azure? Partially. AWS, Azure, and Google Cloud offer data residency controls that keep data within specific geographic regions, and all three offer dedicated infrastructure options. However, full sovereignty over model weights, training data, and system internals is not available through managed cloud AI services – you control where your data is processed but not the model itself. For data residency requirements, managed cloud with appropriate region selection may be sufficient. For full model sovereignty, on-premises or specialist sovereign cloud providers are required.
What open-source models are best for enterprise sovereign AI deployment in 2026? For general enterprise knowledge and productivity: Llama 4 Scout (10M context, best for long-document workflows) or Llama 4 Maverick (highest MMLU). For agentic coding: DeepSeek V4 Pro (MIT licence, leads SWE-Bench among open weights). For European multilingual deployments: Mistral Large 3 or Mistral Small 4 (Apache 2.0, best EU governance alignment). For multilingual workloads across 200+ languages: Qwen 3.5 or Qwen 3.6. For RAG-specific enterprise applications: Cohere Command R+ (self-hosted). For enterprise agentic engineering with maximum licence permissiveness: GLM-5 (MIT). For high-frequency tasks on constrained compute: Phi-4 Mini or Mistral Small 4. Always validate against your specific use case benchmarks on your own data.
How much does it cost to run an on-premises AI model in an enterprise environment? Infrastructure costs for a production enterprise on-premises deployment typically range from $50,000 to $500,000 in upfront GPU hardware depending on throughput requirements, plus $5,000 to $30,000 per month in operational costs (power, cooling, maintenance, engineering time). Bare-metal GPU cloud alternatives (Coreweave, Lambda Labs) offer similar sovereignty characteristics at $2 to $8 per GPU hour with no capital expenditure. The cost compares favourably against high-volume LLM API usage at enterprise scale: at 10 million tokens per day, proprietary API costs can reach $50,000 to $200,000 per month depending on the model tier.
Is sovereign AI the same as local AI? Related but not identical. Local AI typically refers to running models on end-user devices (laptops, phones, edge hardware) – which is a subset of on-premises AI. Sovereign AI is broader, referring to any deployment where the organisation controls data residency and model governance. An organisation running models in its own data centre is doing sovereign AI but not local AI. An organisation running models on employee laptops is doing local AI and sovereign AI simultaneously.
What is the EU AI Act’s impact on sovereign AI adoption? The EU AI Act’s binding enforcement date for high-risk AI systems is 2 August 2026, covering Articles 9–17 and Article 26. Non-compliance exposes organisations to penalties of up to EUR 15 million or 3% of global annual turnover. The compliance requirements technical documentation, conformity assessments, EU AI database registration, event logging, and human oversight mechanisms are significantly easier to satisfy with on-premises or sovereign cloud deployment than with external API-based systems. With an external API, the deploying organisation does not have access to the model internals, training data documentation, or system logs needed to satisfy these requirements. This regulatory pressure is one of the primary drivers of sovereign AI adoption among EU enterprises in 2026.
Conclusion: Sovereignty Is Not Isolation – It Is Control
The misconception about sovereign AI is that it means disconnecting from the AI ecosystem entirely. It does not. A sovereign AI strategy means deploying AI in environments where you have the control, visibility, and governance that your compliance obligations, competitive situation, and risk tolerance require.
For many enterprise workloads, that means keeping sensitive data and regulated processes within owned or jurisdiction-specific infrastructure while using external APIs for lower-sensitivity productivity applications. For organisations in heavily regulated sectors or with genuinely proprietary data assets, it may mean moving the majority of AI workloads to on-premises or sovereign cloud deployment.
The EU AI Act’s 2 August 2026 deadline is imminent. The organisations that have already designed their sovereign AI architecture, rather than discovering the compliance gap when the enforcement date arrives, will have a significant operational and regulatory advantage. For those starting now, the engineering investment in sovereign deployment infrastructure compounds quickly: once you have deployed one model on your own infrastructure, deploying the second is significantly faster and cheaper.
Moweb’s Generative AI & LLM development and AI Security & Governance practices design and build sovereign AI architectures for enterprises in financial services, healthcare, and regulated industries – including on-premises model deployment, RAG pipeline design, access control implementation, and MLOps for self-hosted models. Talk to our team about your sovereign AI requirements.
Found this post insightful? Don’t forget to share it with your network!