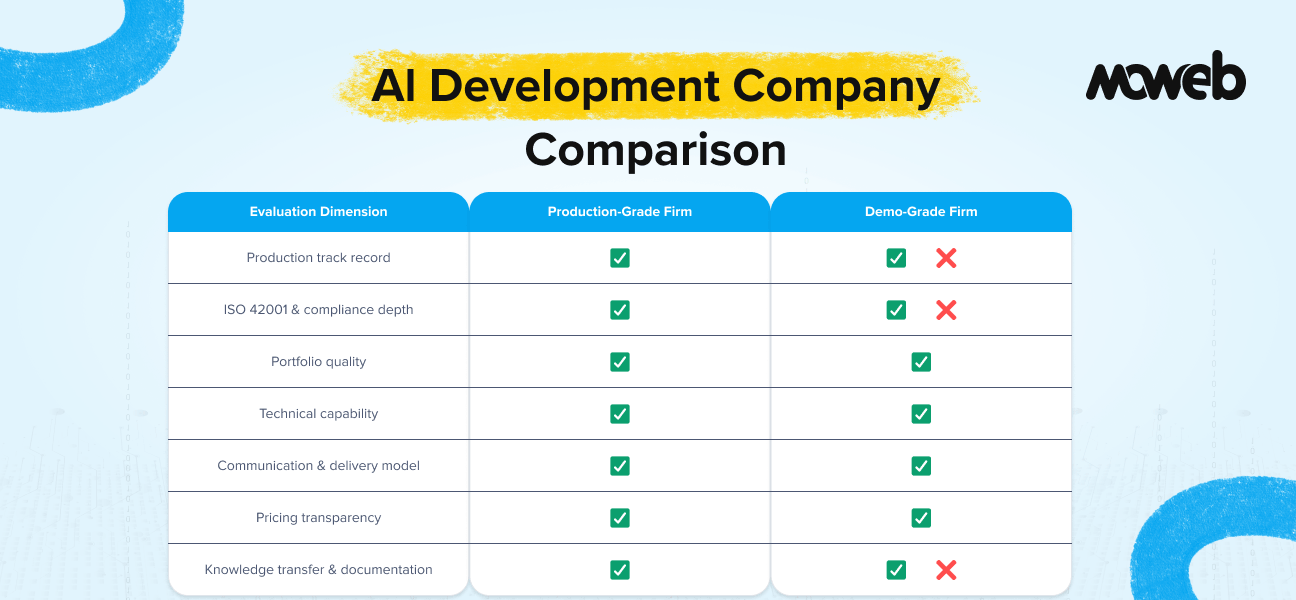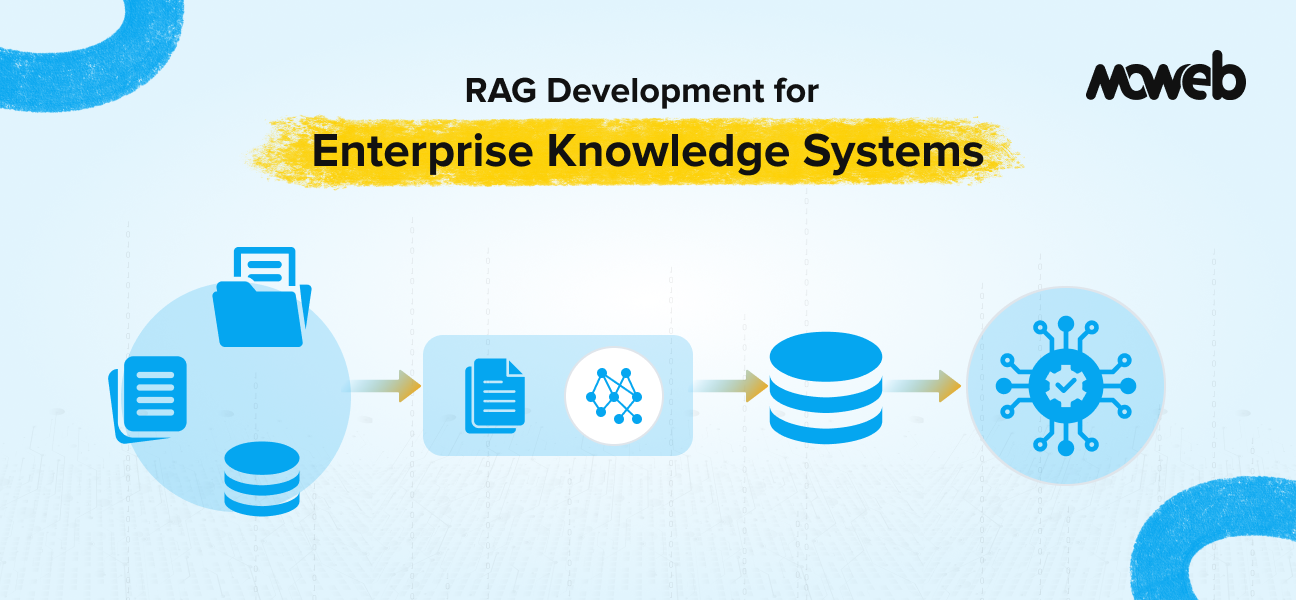
What is RAG development for enterprise knowledge systems? RAG development for enterprise knowledge systems is the process of building a retrieval-augmented generation pipeline that connects a large language model to an organisation’s internal document repositories, databases, and knowledge bases. The result is an AI system that answers questions accurately from your organisation’s own data, with source attribution and access control built in.
What does building an enterprise RAG system involve? It involves five core engineering layers: data ingestion and preparation, chunking and indexing strategy, embedding model selection, retrieval pipeline design (including hybrid search and reranking), and LLM integration with governance controls. Each layer involves distinct architectural decisions that directly affect output quality and system reliability in production.
Most enterprise AI projects that fail do not fail because of the language model. They fail because the data layer was not built properly. The wrong chunking strategy, a poorly configured retrieval pipeline, or a vector database with no access controls will undermine even the best LLM every single time.
This guide is for technical leads, architects, and engineering managers who are past the “what is RAG” stage and need to make real build decisions. It covers the full stack: from how you structure your document corpus, through to the retrieval pipeline, embedding choices, reranking, and the governance controls that make a RAG system safe for enterprise use. If you want the strategic framing first, our guide on what RAG is and when enterprises should use it covers that ground. This one starts where that one ends.
The Architecture Decision You Make Before Writing Any Code
Before you pick a vector database or an embedding model, there is a more fundamental question to answer: what is the shape of your knowledge system?
Enterprise knowledge does not arrive in a uniform format. Most organisations have a mix of structured databases, semi-structured content (JSON, XML, HTML), and unstructured documents (PDFs, Word files, emails, wiki pages). Each type has different requirements for ingestion, chunking, and retrieval. Treating them identically is one of the most common architecture mistakes in enterprise RAG projects.
You need to map your knowledge corpus before you build anything. That means identifying:
- The document types in scope (PDFs, HTML, databases, spreadsheets, tickets, emails)
- The freshness requirements for each type (how often it changes, and how quickly the system needs to reflect updates)
- The access control requirements (who is allowed to retrieve what, and at what granularity)
- The volume of data (the total tokens indexed will determine your vector database choice and indexing cost)
- The query patterns you expect (short factual lookups vs. long reasoning chains vs. multi-document synthesis)
The answers to these questions drive every downstream architectural decision. Skipping this step and going straight to tool selection is why many enterprise RAG projects end up being rebuilt six months after deployment.
Data Ingestion: Getting Your Documents Into the Pipeline
The ingestion layer is responsible for taking raw documents from wherever they live and converting them into a form the rest of the pipeline can work with. This sounds straightforward. In enterprise environments, it almost never is.
Document loaders are the entry point. LangChain and LlamaIndex both provide extensive loader libraries covering PDFs, Word documents, PowerPoint files, HTML pages, Confluence and Notion wikis, Jira tickets, Google Drive, SharePoint, and database tables. For most enterprise deployments, you will use a combination of loaders rather than a single one.
A few things that consistently cause problems at the ingestion stage:
Scanned PDFs need OCR before they can be processed. If your document corpus includes scanned contracts or historical reports, you need an OCR step (Tesseract, AWS Textract, or Azure Document Intelligence) before anything else in the pipeline runs. Sending a scanned PDF directly to a text chunker produces garbage.
Table-heavy documents need special handling. Standard text chunking will break tables across chunk boundaries, destroying the relationships between column headers and cell values. Tools like Unstructured.io have table-aware extraction that keeps table structure intact. For financial documents, compliance reports, or anything with structured tabular data, this matters a lot.
Version control is often overlooked at ingestion design time. If the same document gets updated and re-ingested, you need a clear strategy for handling the old embeddings. Options range from full re-indexing (simple but expensive at scale) to delta-based updates (complex but efficient for large corpora). Whichever you choose, define it before you build, not after your first production incident involving stale data.
Chunking Strategy: The Decision That Affects Everything Downstream
Chunking is the process of splitting documents into segments that will actually be retrieved. It is arguably the most consequential decision in a RAG system because everything downstream depends on whether the retrieved chunks are the right size and shape to answer the queries being asked.
There is no universally correct chunk size. But there are clear principles:
Fixed-size chunking splits text into character or token blocks of a set size, with optional overlap between consecutive chunks. It is simple to implement and works reasonably well for homogeneous corpora like FAQ documents or knowledge base articles. It breaks down for documents with variable structure, where meaningful content does not align with fixed boundaries.
Semantic chunking splits at natural boundaries: sentence endings, paragraph breaks, and section headers. This preserves the logical structure of the content and produces chunks that are coherent as standalone units. It is the preferred approach for most enterprise document types and is now available natively in LlamaIndex’s SemanticSplitterNodeParser.
Hierarchical chunking creates parent and child chunks simultaneously. The child chunks are small and precise, used for retrieval. The parent chunks are larger, providing surrounding context that gets sent to the LLM. This addresses one of the core tensions in chunking: small chunks retrieve precisely but lack context, while large chunks provide context but retrieve imprecisely. LlamaIndex’s ParentDocumentRetriever and similar patterns implement this.
Overlap is important regardless of strategy. A chunk overlap of 10-20% of the chunk size helps prevent answers from being split across chunk boundaries. Without overlap, a sentence that straddles two chunks will never be retrieved cleanly.
For most enterprise knowledge systems, the recommended starting point is semantic chunking with 512-token target chunks, 10% overlap, and metadata tagging at ingestion time. You will almost certainly tune these parameters based on your specific query patterns after running the evaluation. Build evaluation in from day one so you have data to tune against.
Embedding Models: Choosing the Right One for Your Use Case
The embedding model converts text into numerical vectors that make similarity search possible. The choice of embedding model affects retrieval quality more than most teams expect, because different models have different strengths across languages, domains, and document lengths.
Here are the most commonly deployed options in enterprise RAG stacks in 2026:
OpenAI text-embedding-3-large is the current benchmark for English-language general-purpose embeddings. It produces 3072-dimensional vectors (or 256/1536 with dimensionality reduction), has strong performance across most enterprise domains, and is available via API without infrastructure overhead. The main limitation is cost at very high indexing volumes and the fact that data is sent to an external API, which creates compliance considerations for sensitive corpora.
Cohere Embed v3 is a strong alternative with excellent multilingual support and a compressed embedding option that reduces storage costs significantly. It is particularly well-suited to enterprises with multilingual document corpora or strict cost requirements at scale.
BGE-M3 (BAAI) is an open-source embedding model that supports dense, sparse, and multi-vector retrieval in a single model, handles over 100 languages, and can process documents up to 8192 tokens. For enterprises that need full data sovereignty and cannot send document content to an external API, BGE-M3 is currently the strongest self-hosted option.
Domain-specific fine-tuned embeddings are worth considering if your corpus is highly specialised, for example, clinical notes, legal contracts, or financial filings that use domain vocabulary rarely seen in general training data. Fine-tuning an embedding model on a sample of your domain content can produce measurable retrieval improvements, but requires labelled data and infrastructure for the fine-tuning pipeline.
One principle that applies regardless of which model you choose: never mix embeddings from different models in the same index. If you switch embedding models, you need to re-index the entire corpus. Factor this into your operational runbook from the beginning.
Vector Databases: Infrastructure Decisions for Production
The vector database is where your document embeddings live and where similarity search happens at query time. Choosing the wrong one for your scale and access pattern is painful to reverse once you are in production.
Key dimensions to evaluate:
Managed vs. self-hosted. Pinecone and Weaviate Cloud are fully managed and remove infrastructure overhead, but store your vectors in a third-party environment. For enterprises with strict data residency requirements or sensitive data classification, self-hosted options (Milvus, Qdrant, Weaviate open-source) or cloud-provider-native options (pgvector on AWS RDS, Azure Cognitive Search with vector support) are the right path.
Filtering capability. Enterprise RAG almost always requires metadata filtering on top of vector similarity. You need to be able to say “retrieve documents from the legal department, created after January 2025, accessible to the user making this query.” Not all vector databases handle complex compound filters equally well. Qdrant has particularly strong payload filtering. Weaviate handles filtering well in hybrid search contexts. Milvus is strong for high-throughput filtering at a large scale.
Hybrid search support. As covered in Blog #1, hybrid search (combining vector similarity with BM25 keyword search) is the production standard for enterprise RAG. Weaviate has a native hybrid search built in. For Pinecone, you need to implement BM25 externally and merge results. Elasticsearch with vector support handles this well if you are already invested in the Elastic stack. Factor native hybrid support into your decision if you know your use case needs it, and almost all enterprise use cases do.
Scalability characteristics. Pinecone scales horizontally with minimal operational effort. Milvus is designed for very large-scale distributed deployments and is the right choice if you are indexing hundreds of millions of vectors. For most enterprise knowledge systems (tens of millions of vectors or fewer), the differences at scale are not the deciding factor.
Retrieval Pipeline Design: Beyond Simple Similarity Search

A naive retrieval pipeline runs a single vector similarity search and passes the top-k results to the LLM. In a controlled test environment with a clean corpus, this often looks like it works well. In production with messy real-world data, it consistently underperforms.
Production enterprise RAG pipelines use several techniques on top of basic similarity search:
Query rewriting and expansion improve recall by rephrasing the user query before embedding it. A user might ask, “What’s our policy on reimbursing client dinners?” when the relevant document uses the language “entertainment expenses for client-facing activities.” A query rewriting step, either rule-based or LLM-powered, can bridge this gap. HyDE (Hypothetical Document Embeddings) takes this further by having the LLM generate a hypothetical ideal answer and using that as the query vector instead of the original question.
Hybrid retrieval with BM25 combines semantic search results with keyword-based BM25 results, then merges the ranked lists using a reciprocal rank fusion (RRF) algorithm. This is consistently better than either method alone for enterprise data, which tends to have a mix of conceptual content and precise named entities.
Reranking takes the initial retrieved set (typically top-20 or top-50) and applies a cross-encoder model to re-score each document against the query. Cross-encoders are slower than bi-encoders (which is why they are not used for the initial retrieval) but significantly more accurate. The reranked top-k (typically 3-5) is what gets sent to the LLM. Cohere Rerank, Jina Reranker, and BGE-Reranker are the most commonly deployed options. Adding a reranking step is one of the highest-ROI improvements you can make to a RAG system that is already in production.
Multi-query retrieval generates several different phrasings of the original query, retrieves results for each, and deduplicates before reranking. It is particularly useful for ambiguous queries where a single phrasing might miss relevant documents.
Contextual compression takes the retrieved chunks and compresses them, extracting only the sentences directly relevant to the query before passing to the LLM. This reduces prompt length and noise, improving both cost and response quality for long retrieved documents.
LLM Integration: System Prompt Design for RAG
Once you have a well-built retrieval pipeline, the LLM integration layer is where many teams make avoidable mistakes. The system prompt design for a RAG application is different from prompt engineering for a general-purpose assistant.
A well-designed RAG system prompt does three things:
First, it tells the model explicitly to answer only from the provided context and to say clearly when the context does not contain sufficient information to answer the question. Without this instruction, models will hallucinate supplementary information to fill gaps in the retrieved context, which defeats the entire purpose of RAG.
Second, it tells the model how to handle source attribution. If you want responses to cite the document they were retrieved from, the system prompt must specify the format. Consistent source citation is not an automatic behaviour.
Third, it defines the failure behaviour. What should the model say when retrieval returns nothing relevant? “I don’t have enough information to answer that from our knowledge base” is better than a hallucinated answer and better than an unhelpful “I don’t know.”
For the model choice itself, GPT-4o, Claude 3.5 Sonnet, and Gemini 1.5 Pro are all strong choices for enterprise RAG. The differences between them matter less than retrieval quality. A great retrieval pipeline with a mid-tier model almost always outperforms a poor retrieval pipeline with a flagship model.
Access Control: The Enterprise Requirement That Cannot Be Bolted On
Enterprise RAG systems handle data with varying sensitivity levels. Different users should see different documents. An HR team member querying the knowledge base should not be able to retrieve executive compensation data. A contractor should not be able to surface confidential client agreements.
Access control in RAG must be implemented at the retrieval layer, not just the application layer. This means your vector database needs to store metadata indicating the access classification or permitted user groups for each chunk, and your retrieval queries must include a filter that restricts results to documents the requesting user is authorised to see.
Implementing this correctly requires integrating your RAG system with your organisation’s existing identity and access management (IAM) infrastructure. This is not a trivial integration, but it is non-negotiable for enterprise production deployments. Any RAG system that does not enforce access control at retrieval time is a potential data leakage risk, regardless of how well the application layer is secured. Moweb’s AI Security & Governance practice handles this integration as a standard component of enterprise RAG engagements.
RAG Evaluation Framework: How to Know If Your RAG System Is Actually Working
One of the most common gaps in enterprise RAG projects is the absence of a systematic evaluation framework. Teams deploy a system, get positive initial feedback, and assume it is working well. Months later, they discover that retrieval quality has degraded as the corpus grew, or that certain query types were never handled well.
A proper RAG evaluation framework measures several distinct dimensions:
Faithfulness measures whether the generated response is actually supported by the retrieved context. A high faithfulness score means the model is not hallucinating information beyond what it retrieved.
Answer relevance measures whether the response addresses the actual question asked, even if it is technically grounded in the retrieved context.
Context precision measures whether the retrieved chunks are actually relevant to the query. Low context precision means your retrieval is pulling in noise that the LLM then has to ignore.
Context recall measures whether all the information needed to answer the question was actually retrieved. Low context recall means the right documents exist in your index, but are not being found.
Tools like RAGAS (Retrieval Augmented Generation Assessment) provide automated metrics across these dimensions. Running RAGAS evaluations on a curated set of test questions before every significant change to the pipeline gives you a regression baseline. Building this into your CI/CD pipeline means you catch retrieval quality degradation before it reaches users.
One advanced production failure mode that RAGAS does not automatically catch is contradicting retrieved chunks. This occurs when two retrieved documents contain conflicting information about the same topic — for example, a policy document updated in March and an older version from January both indexed in the same corpus. The LLM receives both chunks as context and typically picks one without flagging the conflict, producing a confident answer that may be based on the outdated version. Detection requires human review, sampling of responses in conflict-prone knowledge domains (frequently updated policies, regulatory guidance, versioned product specifications), and a corpus maintenance discipline that removes or clearly supersedes outdated documents rather than simply adding new ones alongside them. This is one of the most common and least visible production quality failures in enterprise RAG systems.
Monitoring and Observability: RAG Latency Optimization and Production Health
A RAG system in production is a distributed pipeline with multiple latency-contributing components: embedding inference, vector database search, reranker scoring, and LLM generation. Monitoring each independently is the only way to diagnose where performance is degrading when overall response times increase.
For RAG latency optimization, track p50, p95, and p99 latency separately for each pipeline stage. The p99 metric — the slowest 1% of requests — reveals tail latency issues that average metrics mask and that directly affect user experience for a meaningful portion of queries. Set hard timeouts on external API calls (embedding model APIs, LLM APIs) and define a graceful degradation path for when those timeouts are hit, rather than allowing a slow external call to stall the entire pipeline.
The tool stack for production observability: Langfuse and Helicone both provide RAG-specific tracing that logs each pipeline stage’s latency, token counts, retrieval scores, and cost per query. This data feeds directly into your evaluation cadence and makes root-cause analysis of quality regressions significantly faster.
Tool Stack Summary: What Moweb Typically Deploys
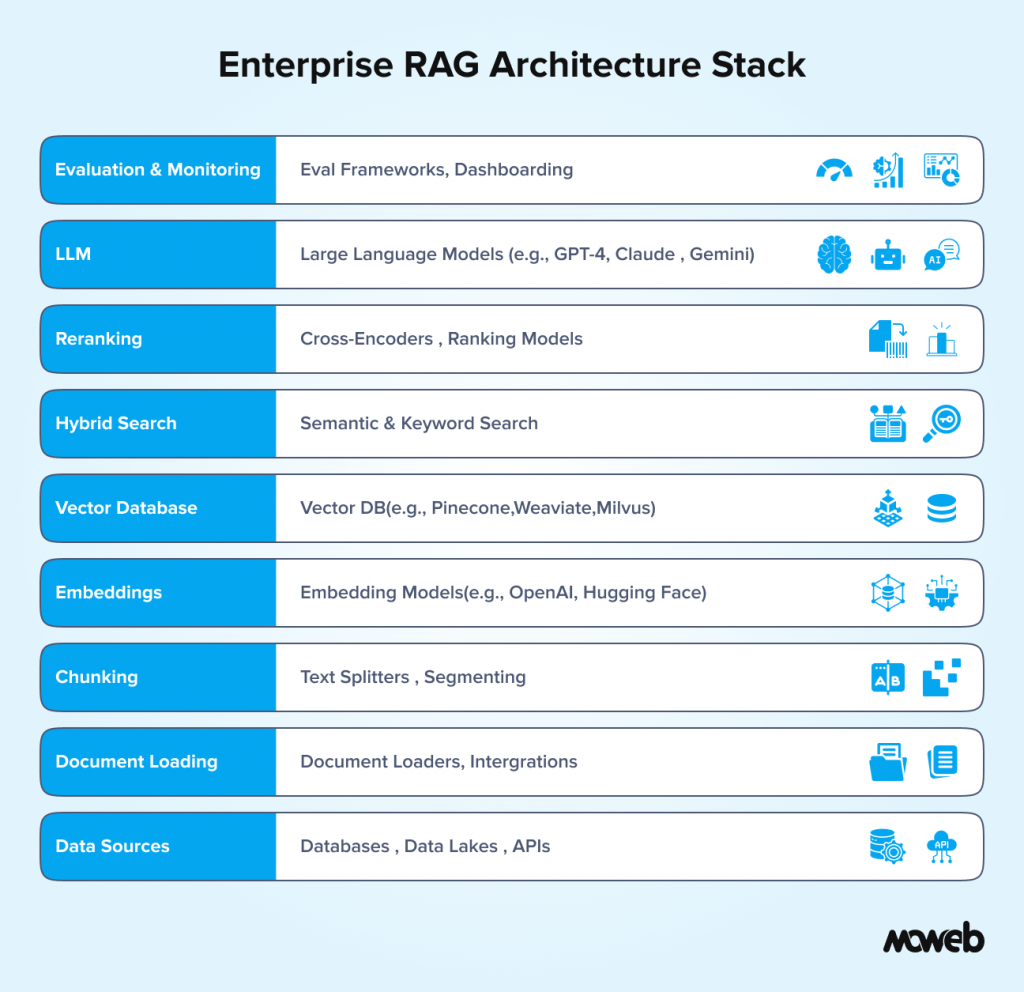
For reference, here is the tool stack we most commonly use for enterprise RAG implementations:
| Layer | Primary Choice | Alternative |
| Orchestration | LangChain / LlamaIndex | Custom pipeline |
| Document loading | LlamaIndex loaders + Unstructured.io | Apache Tika |
| Chunking | LlamaIndex SemanticSplitter | LangChain RecursiveCharacterTextSplitter |
| Embedding model | OpenAI text-embedding-3-large | BGE-M3 (self-hosted) |
| Vector database | Qdrant (self-hosted) or Pinecone (managed) | Weaviate, Milvus |
| Hybrid search | Weaviate native or Elasticsearch | Custom BM25 + RRF merge |
| Reranking | Cohere Rerank | BGE-Reranker |
| LLM | GPT-4o or Claude 3.5 Sonnet | Gemini 1.5 Pro |
| Evaluation | RAGAS | Custom human eval |
| Monitoring | Langfuse | Helicone |
The right choices for your specific deployment depend on your data sovereignty requirements, existing infrastructure, query volume, and budget. There is no universal correct answer, and the best stack is the one that fits your constraints and can be operated reliably by your team.
Conclusion: Build for Production from Day One
The difference between a RAG proof-of-concept that impresses in a demo and a RAG system that performs reliably at enterprise scale is almost entirely in the details covered in this guide. Chunking strategy, hybrid retrieval, reranking, access control, and systematic evaluation are not optional extras to add later. They are the foundation of a system that your organisation can actually trust with real workloads.
Getting these decisions right up front saves months of rework. Getting them wrong means rebuilding core components under production pressure, which is significantly more expensive and disruptive.
If you are planning a RAG implementation and want a technical review of your architecture before you build, Moweb’s Generative AI & LLM development team works through these decisions as part of every engagement. Reach out to start that conversation.
Frequently Asked Questions About Enterprise RAG Development
What is the best chunking strategy for enterprise RAG systems? For most enterprise knowledge systems, semantic chunking is the recommended approach. It splits documents at natural boundaries like sentence and paragraph breaks, producing coherent, standalone chunks. A good starting point is 512-token target chunks with 10% overlap and metadata tagging. For documents where precise retrieval and broad context are both needed, hierarchical chunking (small child chunks for retrieval, larger parent chunks for context) produces the best results. Fixed-size chunking is simpler but works better for homogeneous, well-structured corpora.
Which embedding model should enterprises use for RAG? For English-language general-purpose use cases, OpenAI text-embedding-3-large is currently the strongest option. For multilingual corpora or cost-sensitive high-volume deployments, Cohere Embed v3 is a strong alternative. For enterprises that need full data sovereignty and cannot send content to an external API, BGE-M3 is the best self-hosted open-source option. One critical rule, regardless of model choice: never mix embeddings from different models in the same index, as this will degrade retrieval quality significantly.
What is reranking in a RAG pipeline, and why does it matter? Reranking is a step where an initial set of retrieved documents (typically top-20 or top-50) is re-scored by a cross-encoder model against the original query. Cross-encoders are more accurate than the bi-encoders used for initial retrieval, but too slow for full-corpus search, which is why they are applied as a second-pass filter on the already-retrieved set. Adding a reranking step consistently improves response quality and is one of the highest-impact improvements you can make to a RAG system already in production.
How should access control be implemented in an enterprise RAG system? Access control in enterprise RAG must be enforced at the retrieval layer, not just the application layer. This means storing access metadata (permitted user groups, document classification) alongside each chunk in the vector database, and including access filter conditions in every retrieval query. Implementing this requires integration with your organisation’s existing identity and access management (IAM) infrastructure. A RAG system that relies only on application-layer access controls is a data leakage risk because clever query phrasing can surface unauthorised content in model responses.
What is RAGAS, and how is it used to evaluate RAG systems? RAGAS (Retrieval Augmented Generation Assessment) is an open-source evaluation framework for RAG systems. It measures four core dimensions: faithfulness (does the response reflect only what was retrieved), answer relevance (does the response address the actual question), context precision (are the retrieved chunks relevant to the query), and context recall (was all needed information actually retrieved). Running RAGAS evaluations on a curated test set before each significant pipeline change provides a regression baseline that helps catch quality degradation before it reaches users.
What is hybrid search in RAG, and when should enterprises use it? Hybrid search in RAG combines semantic vector similarity search with traditional keyword-based BM25 retrieval, then merges the ranked results using reciprocal rank fusion. It is the production standard for enterprise RAG because it handles both conceptual similarity (where vector search excels) and precise named entity matching like contract numbers, regulation codes, and product SKUs (where keyword search excels). Most enterprise document corpora contain a mix of both content types, making hybrid search consistently better than either approach alone.
How long does it take to build a production-ready enterprise RAG system? A focused proof-of-concept RAG system on a defined document corpus can be delivered in 3 to 4 weeks. A production-grade enterprise system with proper access control, hybrid search, reranking, evaluation framework, and governance controls typically takes 10 to 16 weeks, depending on corpus complexity, existing infrastructure, and integration requirements. The most time-intensive phase is usually data preparation and access control integration, not the RAG pipeline itself.
Found this post insightful? Don’t forget to share it with your network!