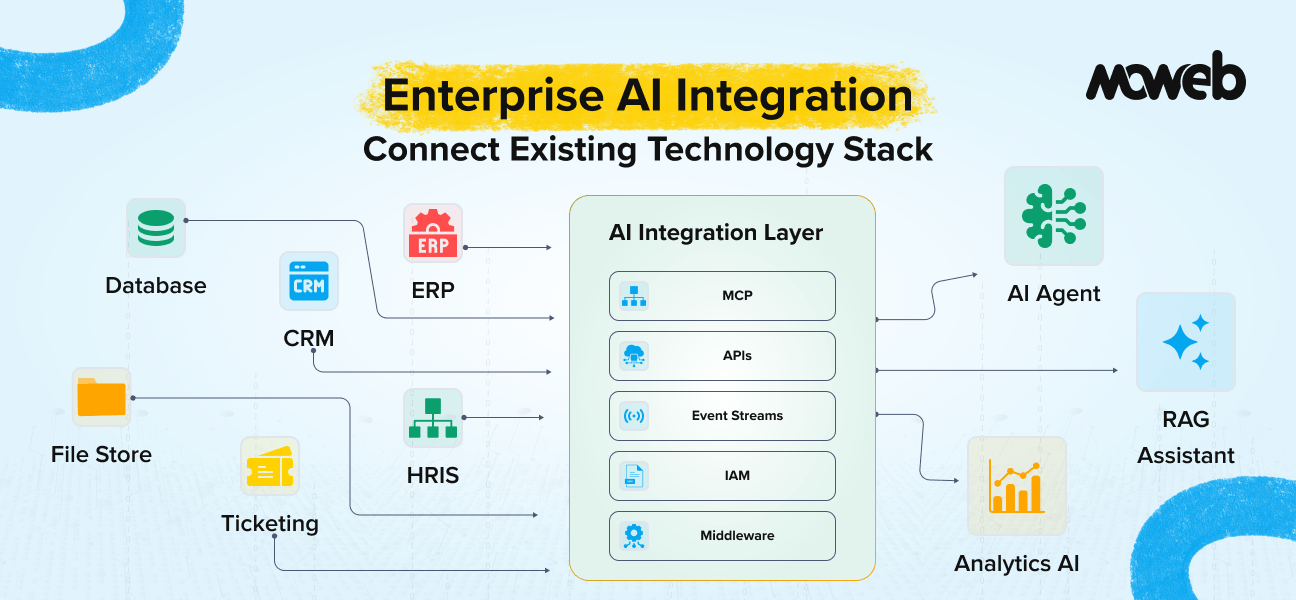
What is enterprise AI integration?Enterprise AI integration is the process of connecting AI systems (LLMs, RAG knowledge assistants, predictive models, AI agents) to the existing technology stack of an organisation – its CRM, ERP, HRIS, ticketing systems, databases, document repositories, and communication platforms – so that AI can access the data it needs, take actions in the systems it needs to act in, and deliver outputs within the workflows where users actually work. Without integration, AI operates in isolation, unable to access organisational data or influence operational processes. 86% of enterprises require upgrades to their existing tech stack to deploy AI agents, and 42% need access to eight or more data sources for their agents to function effectively.
What are the biggest enterprise AI integration challenges? The three most consistently cited enterprise AI integration challenges in 2026 are: legacy system complexity (systems built before APIs were standard, running proprietary protocols, without native integration capability), data fragmentation (relevant data distributed across multiple systems in inconsistent formats without a unified access layer), and security and access control (ensuring AI systems access only the data and perform only the actions they are authorised for, within the organisation’s identity and access management framework). 64% of enterprises lack the architecture required for reliable AI operations, and integration is the most underestimated problem in enterprise AI deployment.
There is a version of enterprise AI integration that is straightforward: a well-documented REST API, a modern cloud-native system, a clean authentication layer, and an AI system designed to connect to it. The integration takes days.
There is the version that most enterprise organisations actually face: a core business system that was implemented in 2011, runs on a vendor platform that does not expose a public API, was customised extensively during implementation in ways the original vendor did not support, and has been maintained by a team that has turned over twice since. Connecting an AI system to this reality takes weeks to months and requires architectural decisions that will affect the entire AI programme’s scalability.
95% of IT leaders cite integration as a challenge to seamless AI implementation (Foundry AI Priorities Study, 2026). 71% of enterprise applications remain unintegrated, a figure that has not moved in three consecutive years. And a 2025 MIT NANDA study found that 95% of generative AI pilot programmes fail to produce measurable financial impact, with the primary cause not model quality but poor workflow integration and misaligned organisational incentives. The implementation gap, the distance between a working AI prototype and a working AI production integration, is consistently the most consequential and most underestimated problem in enterprise AI deployment. Technology is not the bottleneck. Integration, workflow redesign, and organisational change are.
This guide covers the enterprise AI integration landscape honestly: the architectural patterns that work, the legacy system challenges that derail projects, the role of MCP in standardising agent-tool connections, the security requirements that cannot be shortcut, and a phased implementation approach that connects AI to your stack without disrupting operations that the business depends on.
For a full guide to what building enterprise AI agents involves, including the implementation roadmap, see our guide to AI agent development services: use cases, risks, and implementation roadmap.
Why AI Integration Is Different from Traditional System Integration
Enterprise system integration is not new. IT teams have been connecting ERP to CRM, CRM to marketing automation, and marketing automation to analytics platforms for decades. The patterns are well understood: ETL pipelines, REST APIs, webhooks, message queues, and integration platforms like MuleSoft, Dell Boomi, and Azure Integration Services.
AI integration shares some of these patterns but adds requirements that traditional integration does not have.
AI systems need read and write access, not just read. A traditional integration that syncs customer data from CRM to a reporting database is read-only: it moves data for analysis. An AI agent that queries the CRM for account context and then updates the opportunity stage based on its analysis needs write access with a defined scope. The security and access control requirements for write-capable AI integrations are materially more demanding than for read-only data flows.
AI systems need context, not just data. A predictive ML model needs specific feature values. A RAG knowledge assistant needs relevant document chunks. An AI agent needs the full operational context of a task – account history, open tickets, recent communications, current system states – assembled from multiple sources in real time. This context assembly requirement is different from traditional data synchronisation: it is not about moving data between systems on a schedule, it is about retrieving the right data at the moment it is needed for a specific AI task.
By mid-2026, context engineering is emerging as a distinct discipline: multi-agent workflows rapidly expand context requirements as tool definitions, conversation history, and data from multiple sources accumulate simultaneously. The organisations investing in context infrastructure now are minimal, but complete information pipelines are building an advantage that compounds across every AI use case.
AI systems must operate within identity and access boundaries. Traditional integration services typically authenticate with service accounts that have broad access. AI systems that operate on behalf of users must respect user-level permissions: an AI agent helping a sales rep should access only the accounts that the sales rep has permission to see, not all accounts in the CRM. This per-user context propagation through the AI integration layer is an architectural requirement that most traditional integration patterns do not address.
AI outputs need to feed back into operational systems. An AI system that produces a summary, a recommendation, or an action outcome needs mechanisms to write that output back to the relevant operational systems – updating a CRM record, creating a ticket, posting to a communication channel, triggering a workflow. The write-back integration must be scoped, audited, and reversible where possible.
These four requirements shape the architectural decisions at every layer of enterprise AI integration.
The Four Integration Patterns for Enterprise AI
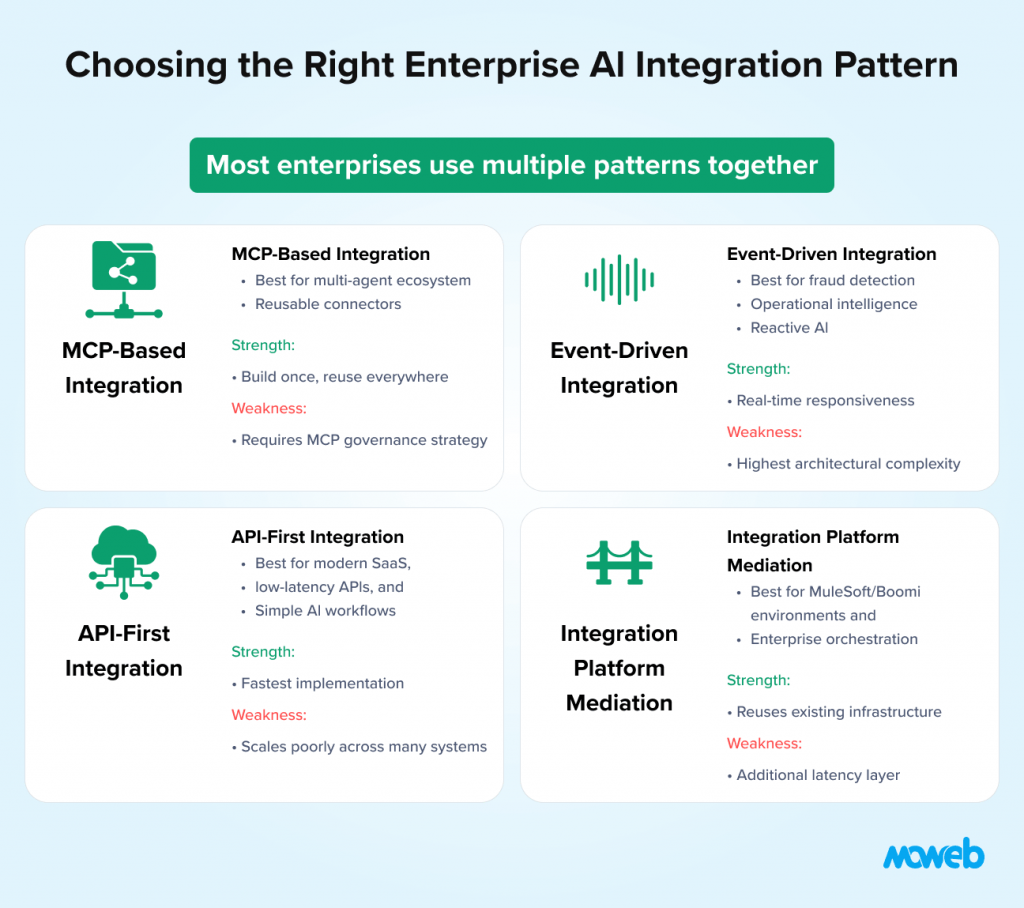
There is no single correct enterprise AI integration architecture. The right pattern depends on the AI use case, the nature of the systems being connected, the organisation’s existing integration infrastructure, and the security and compliance requirements. Four patterns cover the majority of enterprise AI integration scenarios.
Pattern 1: API-First Integration
The cleanest and most scalable integration pattern for AI systems is direct API integration: the AI system calls the APIs of each connected system directly, authenticating with appropriate credentials and querying or writing data as needed.
This pattern works well when:
- The systems being connected expose well-documented, stable REST or GraphQL APIs
- The AI system’s data access requirements are relatively simple and can be served by standard API calls
- The volume of API calls the AI system generates does not exceed API rate limits
The limitation of direct API integration is that each system requires a separate integration: authentication setup, error handling, response parsing, and API versioning for each target system. For AI agents that need to connect to 8 or more data sources, maintaining this many bespoke integrations becomes a significant engineering overhead.
Pattern 2: MCP-Based Tool Integration
Model Context Protocol (MCP) addresses the proliferation problem of direct API integration by providing a standardised communication layer between AI systems and external tools. Rather than building a custom integration for each system, teams build an MCP server for each system once, and any MCP-compatible AI agent can connect to it without additional integration work. MCP was released by Anthropic in November 2024 and has since been adopted as a universal standard: by March 2025, OpenAI added full support across its Agents SDK and ChatGPT desktop; Google DeepMind confirmed MCP support for Gemini; and in December 2025, Anthropic donated MCP to the Agentic AI Foundation (AAIF) under the Linux Foundation with OpenAI, Block, AWS, Google, Microsoft, and Cloudflare as co-founders or supporting members. By early 2026, the MCP Registry listed nearly 2,000 server entries and the Python and TypeScript SDKs alone saw 97 million monthly downloads. The ecosystem includes pre-built servers for Salesforce, GitHub, Jira, Slack, Google Drive, Notion, PostgreSQL, and dozens of other enterprise systems. For systems not yet covered, custom MCP servers can be built to wrap any accessible API.
A critical update for security-conscious enterprise teams: MCP’s authentication model has matured significantly. The June 2025 spec formalised MCP servers as OAuth 2.1 Resource Servers and mandated Resource Indicators (RFC 8707) to prevent token misuse across servers. The November 2025 spec introduced Client ID Metadata Documents as the default client registration mechanism, replacing the prior Dynamic Client Registration approach and enabling secure connections at ecosystem scale. Enterprises evaluating MCP should review these auth requirements as part of their integration security design.
For organisations deploying multiple AI agents that need access to the same enterprise systems, MCP investment compounds significantly: the Salesforce MCP server built for the sales intelligence agent is immediately available for the customer support agent, the account management agent, and any future agent that needs CRM access. Gartner projects that by the end of 2026, 75% of API gateway vendors and 50% of iPaaS vendors will have native MCP features, meaning the integration ecosystem is converging on this protocol as baseline infrastructure. The total integration engineering cost across the AI programme drops with each additional use case.
For a full explanation of how MCP works and why it has become the standard approach for enterprise AI agent tool integration, our guide to what MCP is and why it matters for enterprise AI agents covers the protocol in detail.
Pattern 3: Integration Platform Mediation
For organisations that have already invested in an enterprise integration platform (MuleSoft, Azure Integration Services, Dell Boomi, Workato), the AI integration layer can be built on top of that existing infrastructure rather than alongside it.
In this pattern, the AI system connects to the integration platform, which handles the downstream connections to individual enterprise systems. This approach has advantages for organisations where the integration platform already manages authentication, rate limiting, error handling, and monitoring for the connected systems: the AI system benefits from that existing infrastructure rather than rebuilding it.
The limitation is that integration platforms introduce an additional latency layer. For AI applications with real-time requirements (fraud detection, live customer service interactions, operational monitoring), the additional round-trip through the integration platform may be unacceptable. For batch and near-real-time use cases, the overhead is typically acceptable, and the infrastructure reuse is valuable.
Pattern 4: Event-Driven Integration
Event-driven integration is the pattern for AI applications that need to react to things happening in connected systems rather than query them on demand. An AI system that monitors for contract renewal opportunities, flags compliance risks in real time, or responds to customer churn signals needs to receive events from connected systems as they occur, not poll for updates on a schedule.
In event-driven integration, source systems publish events (a new contract signed, a customer support ticket escalated, a transaction flagged as suspicious) to an event stream platform (Apache Kafka, AWS EventBridge, Azure Service Bus). The AI system subscribes to relevant event streams and processes them as they arrive.
This pattern is more complex to implement than API-based patterns, but is the right choice for AI use cases where latency matters and where the AI system should be reactive rather than on-demand. Financial services AI (fraud detection, real-time risk monitoring), operational intelligence (supply chain disruption detection, predictive maintenance alerts), and customer experience AI (real-time personalisation, proactive support) all benefit from event-driven integration architecture.
In 2026, event-driven architectures are also the foundation for multi-agent systems, where one agent’s output triggers another agent’s action, a pattern Gartner projects will define 70% of AI applications by 2028.
The Legacy System Integration Challenge
The majority of enterprise AI integration complexity comes from legacy systems: core business applications that were implemented before REST APIs were standard, that run on vendor platforms with limited integration capability, or that have accumulated years of customisation that is not documented in the original integration specifications.
According to Foundry’s 2026 AI Priorities Study, 41% of IT leaders identify outdated IT infrastructure as the primary hindrance to AI data utilisation, making legacy architecture the single most concrete technical barrier to AI integration at scale. And a 2026 BigDATAwire analysis notes that 2026 is shaping up as an inflection point for legacy modernisation: generative AI is now capable enough that, in the hands of specialist integrators, rebuilding legacy JMS applications as modern event-driven systems has become commercially viable for the first time.
Three approaches address legacy system integration for AI, in order of investment required:
Wrapper APIs are the fastest path to connecting a legacy system to an AI integration layer. A lightweight API service is built in front of the legacy system, translating between the legacy system’s native interface (a database connection, a SOAP web service, a file-based exchange) and a REST API that the AI system can call. The wrapper handles authentication, request transformation, response parsing, and error handling. The legacy system does not need to change.
Wrapper APIs work well for legacy systems where the required data access patterns are defined and stable. They are less suitable for legacy systems that need to support complex, dynamic queries or where the data model is so inconsistent that the wrapper itself becomes a significant maintenance burden.
Middleware integration uses an integration platform to bridge legacy systems to the AI integration layer. This is effectively Pattern 3 above, applied specifically to legacy systems. The integration platform handles the protocol translation, data transformation, and scheduling that the AI system should not need to manage directly.
Legacy system modernisation is the highest-investment approach and the one that delivers the most durable result: replacing or re-platforming the legacy system itself to expose modern integration interfaces. This is justified when the legacy system is a strategic constraint on multiple AI use cases simultaneously, when the maintenance cost of wrapper approaches has become unsustainable, or when the legacy system’s data model is too inconsistent to support reliable AI integration without a complete restructuring.
For most enterprise AI programmes, the practical approach is to start with wrapper APIs for the most critical legacy systems, accept that some use cases will be constrained by legacy integration limitations, and plan for targeted legacy modernisation as a parallel investment over a 2 to 3 year horizon.
Identity and Access Management Integration
The security requirements of enterprise AI integration – particularly for AI agents that can take actions in connected systems – make identity and access management (IAM) integration one of the most critical architectural decisions in the entire programme.
The requirement is specific: when an AI system operates on behalf of a user, it must inherit that user’s permissions, not operate with the AI system’s own (typically broader) service account permissions. An AI agent that has access to all CRM records because its service account has admin-level access but is assisting a sales rep who should only see their own accounts, is a data governance failure waiting to happen.
Implementing per-user permission inheritance requires integrating the AI system with the organisation’s identity provider (Active Directory, Okta, Azure AD, Google Workspace) at the authentication layer. When a user initiates an AI system interaction, the AI system authenticates on that user’s behalf and carries that user’s permission context through to every downstream API call and database query.A 2025 security analysis found that 97% of organisations hit by an AI-related security incident lacked proper AI access controls, making IAM integration the most consequential security prerequisite for any AI deployment that touches sensitive data.
This is not a technically complex integration, but it is one that is frequently skipped in early AI deployments and creates significant governance exposure. Every AI system that can access sensitive data or take actions in operational systems should have IAM integration as a deployment prerequisite, not a post-launch enhancement.
The additional requirement for AI agents is per-tool permission scoping: each tool or data source the agent can access should be individually authorised, with the minimum permissions required for the agent’s defined task. The principle of least privilege – which applies to all software systems – is especially important for AI agents because their flexible, natural-language-driven behaviour makes unintended data access or action execution more likely than in deterministic software.
For the comprehensive access control framework that AI system integration requires, our guide to AI governance for LLMs and enterprise agents covers the full governance architecture in detail.
Integration Architecture for RAG Knowledge Systems
RAG-based knowledge assistants have specific integration requirements that differ from agent integrations. The primary integration challenge for RAG systems is not at the query-time layer – it is at the indexing layer: getting content from the organisation’s knowledge systems into the vector database in a current, well-structured, access-controlled form.
The key integration points for a RAG knowledge system:
Document source integration connects the indexing pipeline to the systems where organisational knowledge lives: SharePoint or Google Drive for office documents, Confluence or Notion for wikis, Zendesk or Salesforce Knowledge for support content, and custom CMS platforms for product documentation. Each source requires a connector that can authenticate, enumerate available documents, extract content, detect updates, and pass content to the chunking and embedding pipeline.
Access control propagation carries the permissions of each document from the source system into the vector database. A document that is restricted to the Finance department in SharePoint must also be restricted to Finance users in the vector database. The integration must extract permission metadata from the source and attach it to the indexed chunks, and the retrieval queries must apply those permissions as filters.
Update detection and re-indexing handles document changes in the source systems. When a policy document is updated, the old version must be removed from the index and the new version re-indexed. This requires either event-driven update notifications from the source systems or regular delta-sync polling that identifies changed documents without re-processing the entire corpus.
Freshness monitoring tracks the age of indexed content and alerts when documents may be stale relative to their expected update frequency. A regulatory compliance policy that has not been updated in 18 months in a rapidly changing regulatory environment is a knowledge quality risk. MCP’s OAuth 2.1-based authentication model, formalised in mid-2025, provides a standards-compliant framework for implementing this per-tool scoping at the protocol level, making it easier to enforce least-privilege access across all MCP-connected systems from a single governance layer.
For the detailed technical architecture of the RAG system data pipelines, our guide to RAG development for enterprise knowledge systems covers every layer of the implementation.
A Phased Approach to Enterprise AI Integration
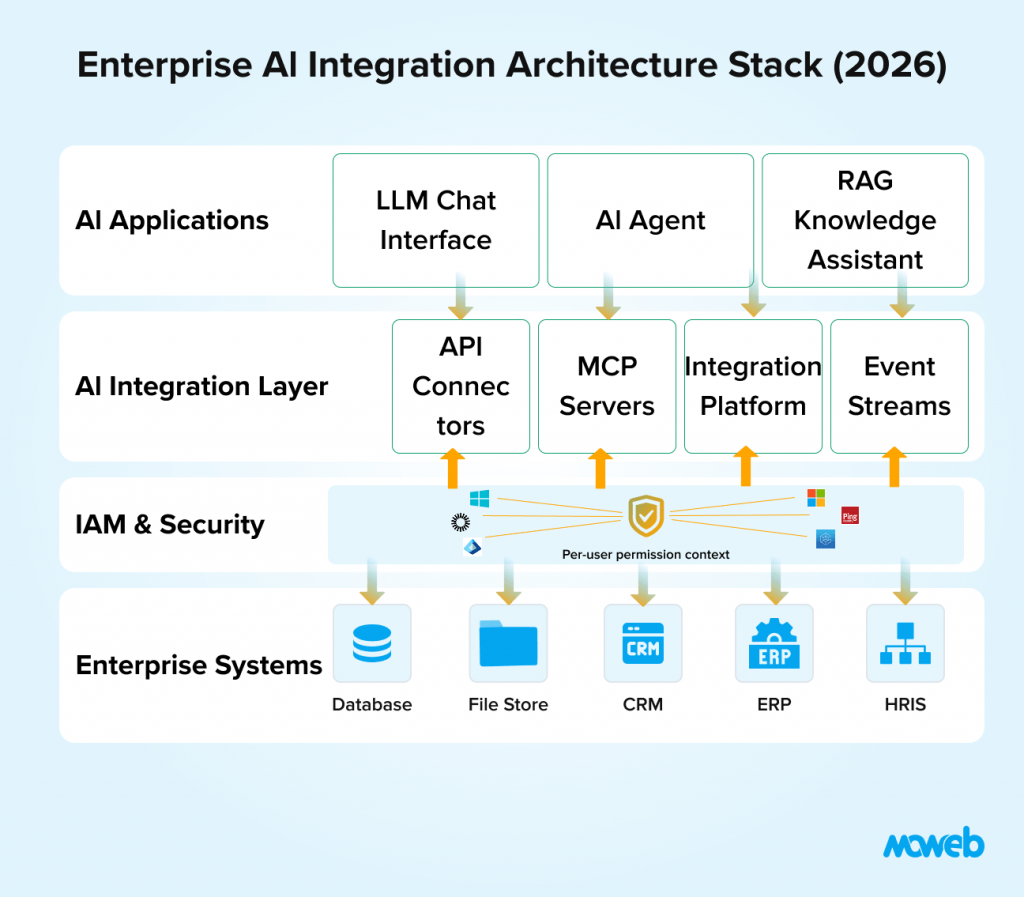
Enterprise AI integration is a programme, not a project. The right approach builds integration capability systematically, reusing infrastructure across use cases rather than building bespoke integrations for each one.
Phase 1 (Weeks 1 to 4): Integration audit and architecture design. Map every system that the prioritised AI use cases need to connect to. Assess each system’s integration capability: does it have a documented API? What authentication mechanisms does it support? What rate limits apply? Are there existing wrapper APIs or integration platform connectors? Identify the highest-priority legacy integration challenges and determine whether wrapper APIs, middleware, or modernisation is the appropriate approach for each.
Design the target integration architecture: which AI systems connect via which pattern, where IAM integration is required, and what the shared integration infrastructure looks like across multiple AI use cases.
Phase 2 (Weeks 4 to 10): Core integration build
Build the integrations required for the first AI use case. For agent-based applications, implement MCP servers for the primary connected systems. For RAG applications, implement the document source connectors and access control propagation layer. For all integrations, implement IAM integration before connecting to production systems. Where possible, select MCP server implementations from the community registry. The MCP Registry now lists nearly 2,000 servers, significantly reducing build time for common enterprise systems.
Establish integration monitoring: logging of all AI system API calls to connected systems, latency tracking, error rate monitoring, and alerting for integration failures.
Phase 3 (Weeks 10 to 16): First AI deployment on integrated stack. Deploy the first AI use case on the integrated stack. Monitor integration performance in production – latency, error rates, permission boundary incidents – and address issues identified during the first production operating period.
Document the integration patterns and configurations established in Phase 2 as reusable components for subsequent AI use cases.
Phase 4 (Ongoing): Integration library expansion. Each subsequent AI use case connects to the existing integration library where possible and adds only the incremental integrations it specifically requires. The MCP servers, IAM integration, and monitoring infrastructure established in Phase 2 compound in value as the AI portfolio grows. The organisations scaling AI fastest in 2026 are those that treat their integration layer as a shared platform with reusable connectors, approved tool catalogues, and governed access policies that any new AI use case can inherit without rebuilding from scratch.
Moweb’s AI Platform Integration practice handles all four phases for enterprise AI programmes, with particular depth in legacy system integration architecture, MCP server development, and IAM integration design.
Frequently Asked Questions About Enterprise AI Integration
What is the hardest part of connecting AI to an enterprise tech stack? Legacy system integration is consistently the hardest part and the most underestimated. Systems built before REST APIs were standard, running on vendor platforms with limited integration capability, or heavily customised during implementation, often require significant wrapper API development or middleware investment. 95% of IT leaders cite systems integration as their top AI implementation challenge (Foundry, 2026), and 41% identify outdated IT infrastructure as the primary barrier to AI data utilisation. The majority of enterprise AI integration engineering effort goes to bridging legacy systems, not to the AI application layer itself.
What is MCP, and why does it matter for enterprise AI integration? MCP (Model Context Protocol) is an open standard released by Anthropic in November 2024 and now governed by the Agentic AI Foundation (AAIF) under the Linux Foundation, co-founded by Anthropic, OpenAI, and Block, with AWS, Google, Microsoft, and Cloudflare as supporting members. By early 2026, the MCP Registry listed nearly 2,000 servers, and the SDKs recorded 97 million monthly downloads. 65% of enterprises plan to adopt MCP or similar standardised AI protocols by the end of 2026 (Gartner), up from just 12% in early 2025. For enterprise AI integration, it means building an MCP server for a system once (Salesforce, Jira, Slack, a custom internal API) makes that system accessible to any MCP-compatible AI agent without additional integration work. For organisations deploying multiple agents, MCP dramatically reduces total integration engineering cost.
How do we ensure AI agents only access data they are authorised to access? Through IAM integration at the authentication layer and the principle of least privilege at the tool permission layer. The AI system must authenticate on behalf of each user, inheriting that user’s permissions rather than operating with broad service account access. Each tool or data source the agent can access should have the minimum permissions required for its defined tasks, explicitly authorised rather than inferred from broad access grants.
Do we need to replace our legacy systems before deploying AI? Not necessarily. Wrapper APIs can bridge legacy systems to AI integration layers without requiring system replacement. The wrapper translates between the legacy system’s native interface and a REST API that the AI system can call. Full legacy modernisation is warranted when the system is a strategic constraint on multiple AI use cases simultaneously, when wrapper maintenance costs have become unsustainable, or when the data model is too inconsistent to support reliable AI integration.
How do we keep RAG knowledge bases current when source documents change? Through update detection integration with source systems: either event-driven notifications from the document store when documents are created, modified, or deleted, or regular delta-sync polling that identifies changed documents without re-processing the entire corpus. Each changed document triggers the removal of the old indexed chunks and re-indexing of the updated content. Freshness monitoring alerts when documents exceed their expected update frequency without being refreshed.
What monitoring should we implement for AI system integrations? At minimum: API call logging (every call the AI system makes to connected systems, with timestamp, user context, and result), latency monitoring (response time of each integration endpoint), error rate monitoring (tracking and alerting on integration failures), permission boundary monitoring (logging when a user or AI system attempts to access data outside their permitted scope), and cost monitoring (API usage costs against budget, particularly important for cloud LLM API calls). Integration monitoring data is also the primary input for governance audits and compliance reviews.
Conclusion: Integration Is the Difference Between AI That Works in a Demo and AI That Works in Your Business
The most capable AI model in the world produces no business value if it cannot access your data and cannot take actions in your systems. Integration is not a technical detail – it is the difference between an AI system that works in a demo and an AI system that works in your business.
The organisations that are extracting genuine operational value from AI in 2026 built their integration architecture before they built their AI applications. They audited their systems, assessed integration complexity, resolved the legacy system challenges that would have blocked production deployment, and built the IAM integration layer that makes AI access compliant and auditable.
The organisations still waiting for their AI pilots to graduate to production are, in the majority of cases, stuck on integration problems that were not anticipated at project start and are now blocking progress mid-build.
Start with the integration architecture. Build the AI application on top of it. The result is a system that actually reaches production and stays reliable over time. Moweb’s AI Platform Integration practice builds enterprise AI integration architectures from the first audit through to production monitoring – including legacy system bridging, MCP server development, IAM integration, and RAG source connectors. Talk to our team about your integration challenges.
Found this post insightful? Don’t forget to share it with your network!