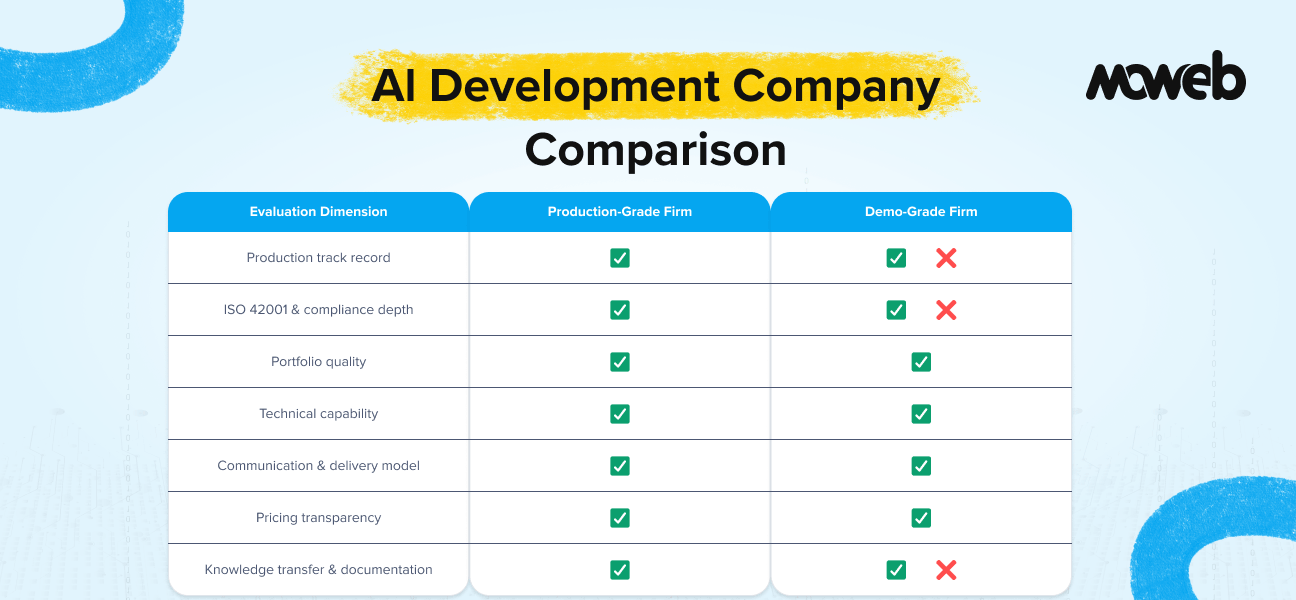
What is RAG in one sentence? Retrieval-Augmented Generation (RAG) is an AI architecture that gives a large language model (LLM) access to your organisation’s private, up-to-date data at the moment of response generation. Instead of answering from memory, the model answers from your documents, databases, and knowledge systems.
When should enterprises use RAG? Enterprises should use RAG when they need an LLM to answer accurately from internal, proprietary, or frequently updated data (such as policy documents, product manuals, compliance guidelines, or customer records) that was never part of the model’s original training.
Your enterprise just deployed a large language model. Within days, your compliance team is flagging incorrect answers. Your support agents are finding the chatbot confidently citing outdated policy. Your engineers are frustrated because the model knows nothing about your internal architecture.
This is not a model problem. It is an architecture problem. And Retrieval-Augmented Generation (RAG) is how enterprises fix it.
What Is RAG? Technical Clarity with Business Relevance
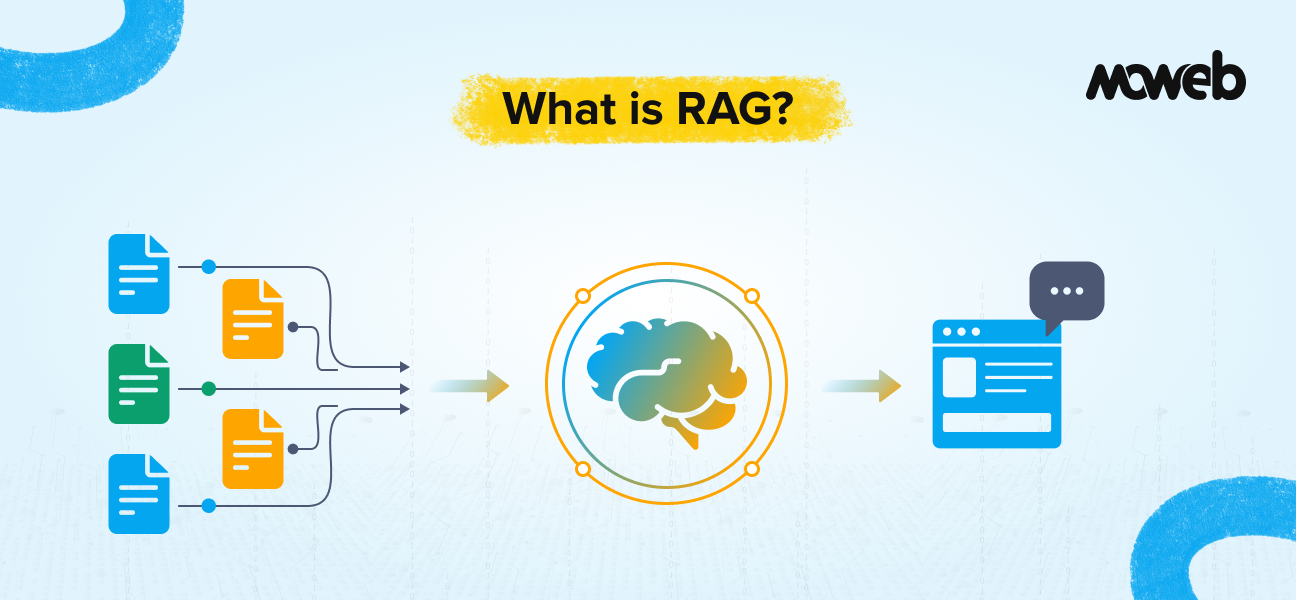
RAG is an AI system design pattern that separates what the model knows from what the model can access. A standard LLM is trained once on a large corpus of public data, and its knowledge is frozen at that point. It cannot read your internal documents. It cannot see last week’s policy update. It has no awareness of your proprietary processes.
RAG changes this by plugging the LLM into a live retrieval layer. When a user submits a query, the system first searches a document store (your documents, your databases, your knowledge bases) and pulls the most relevant content. That retrieved content is then passed to the LLM as context, and the model generates a response grounded in your actual data. This process is formally called LLM grounding, anchoring the model’s outputs to a verified, specific knowledge source rather than allowing it to answer from its general training alone. Grounding is what makes RAG systems trustworthy for enterprise use cases where accuracy and source attribution are non-negotiable.
The model is no longer expected to “know everything.” Instead, it acts as a reasoning layer over your own information. But here is the critical nuance that many enterprise implementations miss: the model’s output quality is directly tied to retrieval quality. If irrelevant, outdated, or poorly structured documents are retrieved, the response degrades regardless of which LLM you use. This is why retrieval architecture and data hygiene are as strategically important as model selection.
RAG Pipeline Architecture: How RAG Works in Enterprise Systems
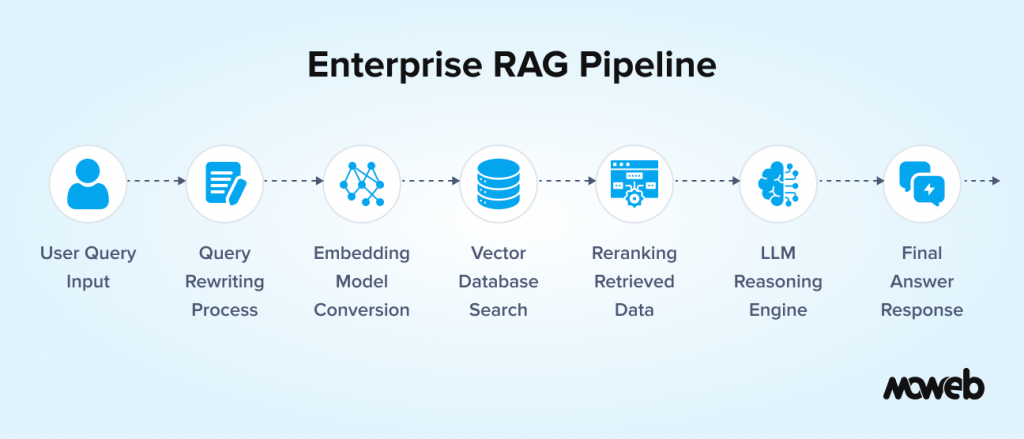
At its most fundamental level, a RAG pipeline flows like this:
- User submits a query – for example: “What is our refund policy for enterprise contracts?”
- Query rewriting – the system may rephrase or expand the query for better retrieval coverage
- Embedding – the query is converted into a numerical vector representation using an embedding model
- Vector database search – the system searches a pre-indexed document store to find semantically similar content
- Reranking – retrieved results are scored and reordered by relevance before passing to the model
- LLM generation – the top retrieved chunks are inserted into the prompt as context, and the LLM generates a response
- Response delivery – the answer is returned, often with source citations
This is the baseline RAG architecture. Enterprise systems in 2026 almost always extend this with query rewriting (to improve recall), hybrid retrieval (combining semantic and keyword search for better precision), reranking layers (to surface the most relevant chunks), and metadata filtering (to enforce data access controls based on user role or department). A production enterprise RAG system is considerably more sophisticated than the basic retrieve-and-generate loop.
The Context Window: Why It Determines What the LLM Can See
Every LLM has a context window — a hard limit on how much text it can process in a single interaction. For enterprise RAG systems, this limit is important because the retrieved document chunks, the user’s query, the system prompt, and the conversation history must all fit within it at the same time.
In practice, this means the retrieval pipeline must select not just the most relevant chunks but the right number of chunks to stay within the model’s context window while providing sufficient information to answer accurately. Retrieve too few chunks and the model lacks the context to answer well. Retrieve too many and you hit the context window limit, increasing cost and potentially diluting the most relevant content with less relevant material.
Modern enterprise RAG systems manage this with contextual compression (trimming retrieved chunks to the most relevant sentences before passing to the LLM) and by selecting models with larger context windows (GPT-4o supports 128K tokens, Claude 3.5 Sonnet supports 200K tokens) for use cases that require broad cross-document reasoning. Context window size is one of the practical considerations in LLM selection for enterprise RAG deployments.
Vector Databases: The Storage Layer That Makes RAG Possible
For RAG to work, your documents must first be converted into vector embeddings and indexed in a database designed for fast similarity search. This is called the indexing phase, and it runs offline before any user queries arrive.
The most commonly deployed vector databases in enterprise RAG stacks right now include:
- Pinecone – a fully managed, cloud-native vector database built for production scale, particularly popular for enterprises that want to avoid infrastructure overhead
- Weaviate – open-source with enterprise cloud options, strong for hybrid search combining vectors with keyword filters
- Milvus – an open-source distributed vector database well-suited to large-scale, high-throughput enterprise deployments
- Qdrant – high-performance, Rust-based vector search with strong filtering capabilities; increasingly preferred for latency-sensitive applications
- PostgreSQL with pgvector – for teams already on Postgres who want to add vector search without introducing a new infrastructure dependency, at the cost of some performance at very large scale
Choosing the right vector database depends on your data volume, query latency requirements, existing infrastructure, and whether you need managed hosting or full data sovereignty. There is no universal right answer.
Passage-Level Indexing and Chunking: Why Structure Matters
Before your documents can be indexed, they must be split into passages or chunks. These are discrete segments of text that the retrieval system can fetch individually. How you chunk your documents has a dramatic effect on retrieval quality.
Chunk too large, and you retrieve irrelevant surrounding content alongside the answer. Chunk too small, and you lose the context that makes a passage meaningful. Most production systems use semantic chunking – splitting at natural sentence or paragraph boundaries with some overlap between chunks – rather than fixed-size character limits.
Beyond chunking strategy, metadata is equally important. Each chunk should carry metadata tags such as document source, creation date, department, access classification, and version number. Without metadata, you cannot filter results by relevance signals beyond semantic similarity, and you cannot enforce access control at retrieval time.
Hybrid Search: Why Vector-Only RAG Is No Longer Enough
Early RAG implementations relied purely on vector similarity search. In 2026, the production standard for enterprise systems has shifted to hybrid search, which combines semantic vector search with traditional keyword-based retrieval (typically BM25, the algorithm underlying most full-text search engines).
Why does this matter? Vector search is excellent at capturing conceptual similarity; it finds documents that mean the same thing even when the exact words differ. But keyword search is better at precision for named entities, product codes, regulatory references, and technical terms where exact matching beats fuzzy similarity. Enterprise data is full of such content: contract numbers, regulation codes, SKUs, employee IDs.
Hybrid search engines blend both signals, often with a reranking model on top to produce a final ordered result set. Systems like Weaviate and Elasticsearch with vector support have built this in natively. For most enterprise deployments today, a pure vector search RAG system should be considered a starting point, not a final architecture.
Agentic RAG and Graph RAG: Where Enterprise AI Is Heading in 2026
The RAG conversation has moved significantly in the past twelve months. Two developments are reshaping how enterprises think about this architecture.
Agentic RAG extends the basic retrieve-and-generate model by placing an AI agent in control of the retrieval process. Rather than executing a single retrieval step in response to a query, an agent can decide when to retrieve, what to retrieve, from which source, and how many times to iterate before producing a final answer. For complex queries that span multiple documents or require multi-step reasoning (a contract review that references three different policy documents, for example) agentic RAG produces dramatically better results than a single-pass retrieval pipeline. Frameworks like LangGraph and LlamaIndex Workflows are the primary implementation tools here.
Graph RAG, popularised by Microsoft Research’s GraphRAG project, takes a different approach. Instead of retrieving flat chunks of text, Graph RAG builds a knowledge graph from your document corpus, encoding entities and their relationships. When you query it, you get not just relevant passages but structured relational context: this product is subject to this regulation, which is enforced by this authority, which has jurisdiction over these regions. For use cases involving complex organisational knowledge, legal and compliance data, or large interconnected datasets, Graph RAG often produces significantly more coherent answers than standard vector retrieval.
Both approaches represent the direction enterprise RAG is moving. Understanding them matters even if your first deployment is a simpler system, because your architecture today will need to accommodate these patterns as your use cases mature.
When Should Enterprises Use RAG? The RAG Readiness Matrix

Not every AI use case needs RAG. Choosing it when you don’t need it adds complexity; not choosing it when you do leads to hallucination, inaccuracy, and compliance risk. A RAG readiness assessment — an honest evaluation of your data, use case, and compliance context against the signals below — is the most practical way to make this decision before committing budget. Here is the framework:
Strong signals that RAG is the right choice:
- Your use case requires answers drawn from internal, proprietary, or confidential documents that no public LLM has ever seen
- Your source data changes frequently (policies update, product specs evolve, regulations shift) and you need the AI to reflect current information without retraining
- Your organisation needs to audit AI responses by tracing them back to specific source documents
- Your use case spans a large document corpus (hundreds to thousands of documents) where fine-tuning would be prohibitively expensive to maintain
- You are operating in a regulated environment where explainability and source attribution are compliance requirements
Signals that RAG may not be the right choice:
- Your primary goal is to change how the model responds (its tone, format, or domain vocabulary) rather than what it knows. Fine-tuning is better for this.
- Your data is entirely static, already well-represented in public training data, and your use case doesn’t require source attribution. A well-prompted base model may suffice.
- Your query volume and latency requirements make retrieval overhead impractical at your scale without significant infrastructure investment.
Use this as a starting decision tool, not a final one. Complex enterprise deployments often combine RAG with fine-tuning: fine-tuning shapes model behaviour, and RAG supplies current knowledge.
RAG vs. Fine-Tuning vs. Prompt Engineering: A Practical Comparison
This is the question every enterprise AI team faces at the start of a project. Here is an honest comparison across the dimensions that matter most for enterprise decisions:
| Dimension | Prompt Engineering | Fine-Tuning | RAG |
| What it changes | How the model is instructed | Model weights and behaviour | What the model can access |
| Use private/internal data | No | Yes (embedded in weights) | Yes (retrieved at runtime) |
| Handles data updates | No | Requires retraining | Yes (re-index, no retrain) |
| Source attribution | Not possible | Not possible | Native |
| Setup cost | Low | Medium–High | Medium |
| Ongoing cost | Minimal | High (retraining per update) | Low–Medium (re-indexing) |
| Response latency | Lowest | Lowest | Slightly higher (retrieval step) |
| Hallucination risk | High | Medium | Low (when retrieval is accurate) |
| Best for | Format, tone, and task framing | Domain-specific style and behaviour | Accurate, current, sourced answers from your data |
The honest takeaway: most enterprise deployments use all three. You fine-tune or prompt-engineer for model behaviour, and you use RAG to give the model access to your actual data.
RAG Security: What Enterprises Must Address Before Going to Production
Security in enterprise RAG systems is more complex than in standard application development, and the most common vulnerabilities are not well understood by teams without specific AI security expertise. The OWASP LLM Top 10 is the definitive reference for large language model application security and identifies several risks directly relevant to RAG deployments.
Prompt injection is the most widely exploited. An attacker can embed malicious instructions inside a document that ends up in the retrieval context, causing the model to execute unintended actions or leak information. In a RAG system where user-submitted documents are part of the knowledge base, this attack surface is significant.
Unauthorised data retrieval occurs when users can effectively query documents they should not have access to. If your vector database indexes sensitive documents without per-user or per-role access filtering, a carefully worded query can surface confidential content in a response even if the user never sees the raw document. Your retrieval architecture must enforce the same access controls as your document management system.
Data exfiltration via the response layer is a subtler risk. A model that has retrieved sensitive context can be manipulated through prompt injection or direct adversarial queries to include that information in its output. Rate limiting, output scanning, and retrieval audit trails are the primary defences.
Addressing these risks requires a governance framework built around your RAG architecture from day one, not bolted on after deployment. Moweb’s AI Security & Governance practice covers this end-to-end for enterprise implementations.
RAG Implementation: A 7-Step Enterprise Roadmap
Building a production-grade RAG system for an enterprise is a structured engineering process, not a plug-and-play integration. Here is the sequence that leads to reliable outcomes:
- Data audit and preparation – Identify the document corpus, assess data quality, establish access permissions, and define the metadata schema. This step is frequently underestimated and is the single biggest cause of RAG failures in production.
- Chunking strategy design – Define chunk size, overlap, and semantic boundaries appropriate to your document types. PDFs, HTML pages, internal wikis, and database records each need different treatment.
- Embedding model selection – Choose an embedding model aligned to your language, domain vocabulary, and latency requirements. OpenAI’s text-embedding-3, Cohere Embed, and open-source alternatives like BGE each have different trade-offs.
- Vector database setup and indexing – Deploy and configure your chosen vector store, run the indexing pipeline, and validate retrieval quality on representative test queries.
- Retrieval pipeline configuration – Implement hybrid search if required, set up reranking, and define metadata filters for access control.
- LLM integration and prompt design – Connect the retrieval output to your LLM of choice (GPT-4o, Claude, Gemini, or an open-source model), design the system prompt to use retrieved context effectively, and handle failure cases where retrieval returns nothing useful.
- Governance, monitoring, and evaluation – Implement logging of all queries and retrieved sources, define evaluation metrics (faithfulness, answer relevance, context precision), and establish a human review process for high-stakes outputs.
Steps 1 and 7 are consistently where enterprise RAG projects succeed or fail. Everything in between is solvable with the right engineering. Data quality and governance are cultural and organisational challenges that require senior stakeholder alignment.
Real-World Enterprise RAG Use Cases
RAG is being deployed across industries in use cases that range from straightforward to highly complex:
- Legal and compliance teams using RAG to query contracts, regulatory documents, and policy libraries, getting sourced, auditable answers instead of generic LLM responses
- Enterprise support and service desks deploying RAG-powered assistants that answer from product documentation, troubleshooting guides, and historical ticket resolutions, reducing resolution time significantly
- Financial services using RAG to surface relevant precedents from internal research repositories, regulatory filings, and risk documentation for analyst workflows
- Healthcare operations querying clinical guidelines, formularies, and standard operating procedures, with source attribution essential for compliance and clinical governance
- Manufacturing and field operations giving service engineers access to maintenance manuals, parts databases, and incident histories via a natural language interface
Moweb has delivered RAG implementations across data engineering, enterprise software, and AI platform integration engagements. If you want to understand what a production deployment looks like for your industry, the Generative AI & LLM services page covers our specific capabilities and delivery approach.
Frequently Asked Questions About RAG for Enterprises
What is Retrieval-Augmented Generation (RAG)? Retrieval-Augmented Generation (RAG) is an AI architecture that connects a large language model to an external knowledge source, typically a vector database containing your organisation’s private documents, so the model can retrieve relevant information at query time rather than relying solely on what it learned during training. This allows the model to give accurate, current, and sourced answers based on your actual data.
When should an enterprise use RAG instead of fine-tuning? Enterprises should use RAG when they need the AI to answer from frequently updated, proprietary, or compliance-sensitive documents and need source attribution for auditability. Fine-tuning is better when you want to change the model’s behaviour, tone, or domain-specific response style. Many production systems combine both: fine-tuning shapes how the model responds, while RAG determines what it can access.
What is the difference between RAG and a vector database? A vector database is a component within a RAG system. It is the storage and retrieval layer that holds document embeddings and enables fast similarity search. RAG is the full architecture that includes document ingestion, chunking, embedding, retrieval from the vector database, and LLM-based response generation. You cannot have RAG without a vector database, but a vector database alone is not RAG.
What is Agentic RAG and how is it different from standard RAG? Agentic RAG places an AI agent in control of the retrieval process, allowing it to decide when to retrieve, what to retrieve, from which source, and whether to iterate multiple retrieval steps before generating a final answer. Standard RAG executes one fixed retrieval pass per query. Agentic RAG is better for complex, multi-step queries that span multiple documents or require reasoning across different knowledge sources.
What is Graph RAG and when should enterprises consider it? Graph RAG, popularised by Microsoft Research’s GraphRAG project, builds a knowledge graph from your document corpus, encoding entities and their relationships rather than storing isolated text chunks. It is particularly effective for use cases involving complex organisational knowledge, legal and compliance data, or large interconnected datasets where understanding relationships between entities matters as much as retrieving relevant passages.
What are the main security risks in enterprise RAG systems? The primary security risks include prompt injection (malicious instructions embedded in retrieved documents that manipulate the model), unauthorised data retrieval (users surfacing confidential content through cleverly worded queries when access controls are not applied at the retrieval layer), and data exfiltration via the response layer. The OWASP LLM Top 10 is the authoritative reference for managing these risks. Governance, access control at the vector database level, and output monitoring are the core mitigations.
How long does it take to build a production-ready RAG system for an enterprise? A production-ready enterprise RAG system typically takes 8 to 16 weeks, depending on the size and complexity of the document corpus, the existing data infrastructure, access control requirements, and the integration complexity with existing enterprise systems. A focused proof-of-concept on a single document set can often be delivered in 3 to 4 weeks. The most time-consuming phase is usually data preparation and governance setup, not the technical RAG pipeline itself.
Conclusion: RAG Is Architecture, Not a Feature
The most important thing to understand about RAG is that it is an architectural decision, not a feature you turn on. Getting it right in enterprise environments requires careful thinking about data quality, retrieval design, security, access control, and ongoing governance. All of this must be in place before a single user query is ever processed.
When it is done well, RAG closes the single biggest gap in enterprise AI deployment: the gap between what an LLM was trained on and what your organisation actually knows. It makes AI responses accurate, auditable, and current. It makes compliance teams less nervous and business leaders more confident. And it creates a foundation on which more advanced capabilities (agentic AI, multi-source reasoning, Graph RAG) can be built as your maturity increases.
If your LLM is hallucinating, cannot access your internal data, or produces answers you cannot trace back to a source, the architecture is the problem. Not the model. Talk to Moweb’s AI team about what a well-built RAG system looks like for your specific context.
Found this post insightful? Don’t forget to share it with your network!