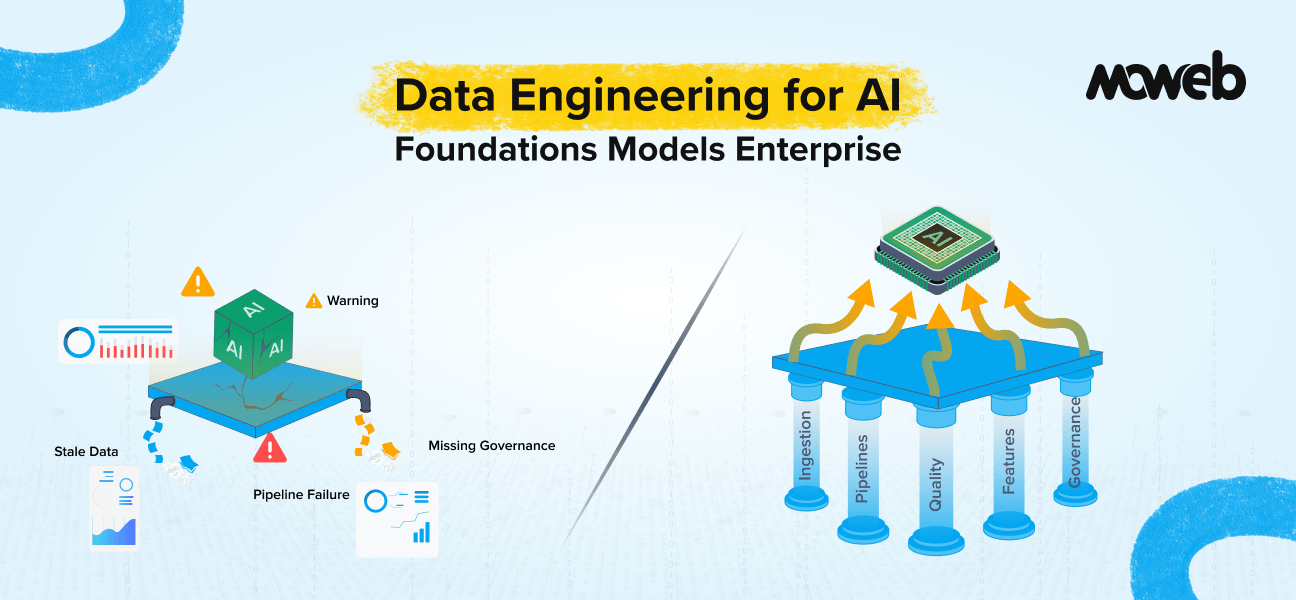
What is data engineering for AI, and why does it matter? Data engineering for AI is the discipline of building and maintaining the data infrastructure that AI and machine learning systems depend on: data pipelines that ingest and transform data from source systems, data quality frameworks that ensure models train and run on accurate and consistent data, feature stores that make the right data available to models at both training and serving time, and data governance structures that ensure compliance, lineage, and auditability. 90% of AI and machine learning projects depend directly on data engineering pipelines, and 80% or more of enterprise AI initiative failures are caused by data engineering problems not by limitations of the AI models themselves.
What data infrastructure does an enterprise need before deploying AI? At minimum, enterprises need five data infrastructure components before AI deployment can succeed: a centralised data store (data warehouse or data lake) that consolidates data from source systems in a queryable format; reliable data pipelines that keep that store current with acceptable freshness for the intended AI use cases; documented data quality standards with automated monitoring; a feature store (for predictive ML use cases) that ensures consistent feature computation between training and production; and data governance covering access controls, lineage tracking, and compliance with relevant data protection regulations. Without these foundations, AI systems will produce unreliable outputs regardless of model quality.
Here is a scenario that plays out across enterprises every quarter: the AI vendor delivers the model, the data science team validates it in evaluation, results look compelling, then the system hits production, and outputs are wrong, inconsistent, or weeks stale. The post-mortem blames the model. The model is rarely the cause.
According to current research, 80% or more of enterprise AI initiative failures are caused by data engineering problems – not limitations of the AI models themselves. Projects with strong data engineering foundations are three times more likely to reach production. Organisations with successful AI initiatives invest up to four times more in data and analytics foundations compared to those experiencing poor AI outcomes, according to Gartner’s April 2026 analysis of 353 data and analytics leaders.
The uncomfortable truth that most AI vendors will not tell you upfront: the model is not the problem. The data is. And fixing the data is not a cleanup exercise you run alongside AI development – it is a prerequisite that must precede it. Before you sign an AI contract, read this guide.
This guide covers what AI-ready data engineering actually means in 2026, the five infrastructure layers that determine whether AI systems produce reliable outputs, the most common data engineering failures that stall AI programmes, and a phased roadmap for building the foundation that every AI use case your organisation will ever deploy depends on. We also address how to evaluate your current data maturity before committing to a budget. See our AI readiness assessment checklist for mid-sized enterprises.
Why Data Engineering Is the Binding Constraint on Enterprise AI
The relationship between data engineering quality and AI project success is not subtle. It is quantifiable, consistent, and appears across every major study of enterprise AI adoption in 2025 and 2026.
90% of AI and machine learning projects depend directly on data engineering pipelines. The model itself – the LLM, the predictive ML algorithm, the RAG retrieval system – is the visible surface of an AI deployment. The data infrastructure beneath it is invisible until it fails. When it fails, it fails in ways that are expensive to diagnose and difficult to fix under production pressure.
The pattern is consistent across enterprise contexts: an organisation starts an AI project, signs a contract with a model vendor or cloud provider, and then discovers 10 to 14 weeks into the project that the data is not ready. No unified customer identifier. No consistent product taxonomy across systems. No pipeline to bring real-time signals into the feature layer. The AI project stalls. The timeline doubles. The budget erodes. This is not an edge case. It is the pattern.
Organisations with legacy ERP and CRM infrastructure typically spend 70 to 80% of their IT budgets on system maintenance, leaving almost nothing for the data engineering work that AI actually needs. The data problem has been invisible because the cost of untrustworthy data was absorbed as operational friction rather than recognised as a structural constraint on strategic capability.
In 2026, with AI adoption pressure across every enterprise function, the data problem is impossible to hide. The organisations pulling ahead on AI ROI are the ones that recognised this early and invested in the data foundations before the AI systems that depend on them. A structured AI readiness assessment that includes data infrastructure as a first-dimension check is the most practical starting point before committing to an AI investment.
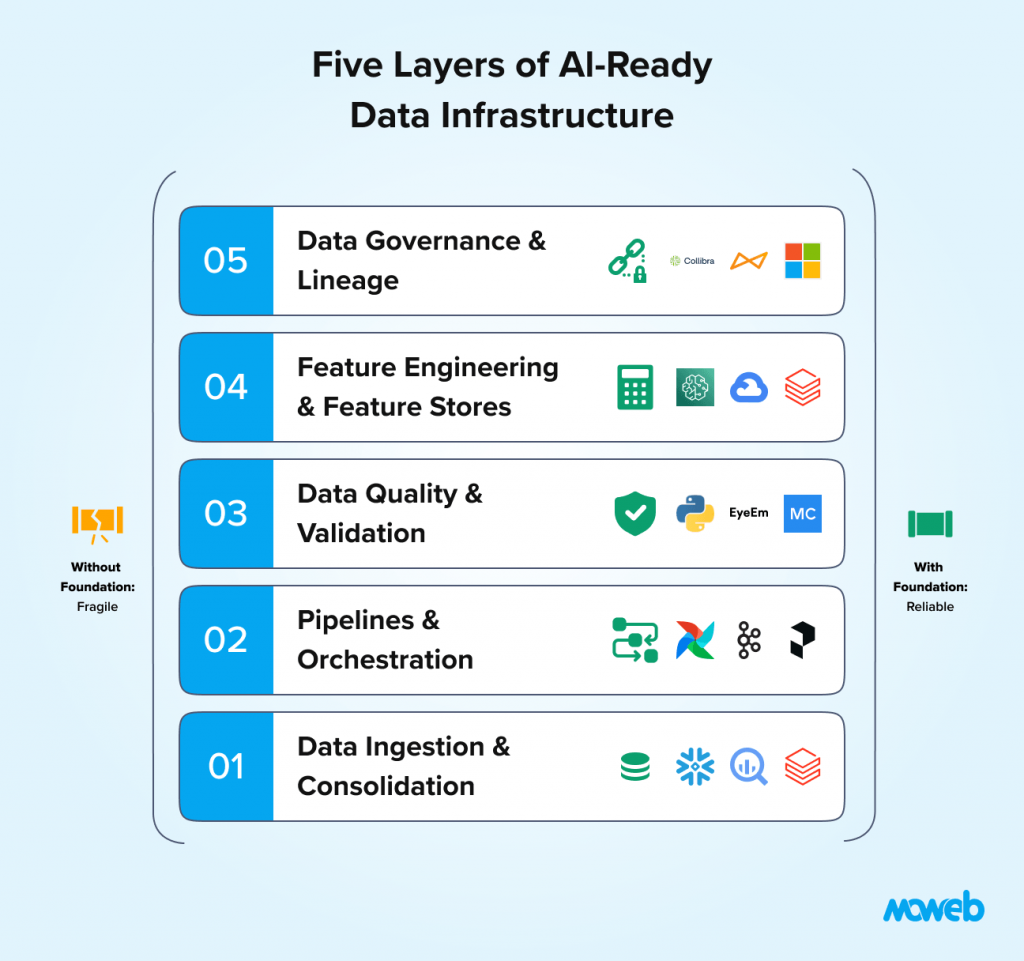
Layer 1: Data Ingestion and Consolidation
The first layer of AI-ready data infrastructure is a consolidated data store that makes your organisation’s data accessible in a queryable, consistent format. Most enterprise data lives in source systems – ERP, CRM, HRIS, ticketing systems, operational databases, and SaaS applications – that were not designed to share data or to work with AI systems.
Getting from fragmented source systems to a unified data layer is the foundational engineering challenge. Three architectural patterns are relevant in 2026:
The modern cloud data warehouse (Snowflake, Google BigQuery, AWS Redshift, Azure Synapse) consolidates structured and semi-structured data from operational systems into a centralised analytical store. It is the right choice for organisations where the primary AI and analytics use cases operate on structured business data and where query latency of seconds to minutes is acceptable. 85% or more of new data engineering workloads run on cloud platforms as of 2026, and the cloud data warehouse is the default entry point for most mid-market enterprises building their AI data foundation.
The data lake or lakehouse (Databricks, AWS S3 with Delta Lake, Azure Data Lake Storage with Apache Iceberg) handles unstructured and semi-structured data alongside structured data at a lower storage cost. It is the right choice when the AI use cases require processing documents, images, log files, or other unstructured content alongside structured business data, which is the case for most RAG systems, computer vision applications, and NLP models.
The streaming data platform (Apache Kafka, AWS Kinesis, Azure Event Hub) handles real-time data ingestion from operational systems, IoT sensors, and event streams. It is the right choice when AI applications require near-real-time data freshness – fraud detection, real-time recommendation, and live operational monitoring. 45% or more of new data pipelines are being built for real-time or near-real-time processing in 2026.
Most enterprise AI programmes eventually need all three – the warehouse for historical structured analytics, the lakehouse for unstructured content and large-scale ML training data, and the streaming platform for real-time AI applications. Starting with the warehouse is typically the right first move for organisations building their AI data foundation, because it addresses the most common immediate AI use cases and provides the most accessible starting point for teams without streaming infrastructure experience.
Layer 2: Data Pipelines and Orchestration
Data pipelines are the engineering infrastructure that moves data from source systems to the consolidated store, transforms it into the formats AI systems need, and keeps it current. They are the most consistently underestimated component of AI data infrastructure.
30 to 40% of data pipelines experience failures every week in enterprise environments. Pipeline failures mean stale data in the consolidated store, which means AI systems trained or running on outdated information – a direct path to unreliable outputs. Data downtime costs large organisations millions of dollars annually in decision quality degradation before the cost is recognised as a pipeline problem.
AI-ready data pipelines have requirements that standard BI-oriented pipelines often do not meet:
Freshness requirements are more demanding. A BI dashboard that is updated nightly is useful for most reporting needs. A fraud detection model that relies on transaction features needs data that is seconds to minutes old, not hours. The freshness requirement of each AI use case must drive the pipeline design, not the other way around.
Lineage tracking is mandatory, not optional. AI governance requirements in regulated environments demand the ability to trace exactly which data, from which source, at what point in time, was used to train or run a specific model. This means pipelines must emit lineage metadata at every transformation step, not just at ingestion.
Schema evolution must be handled gracefully. Source systems change their data schemas over time – new fields are added, existing fields are renamed or removed, and data types change. A pipeline that breaks silently when a source schema changes is a production liability. AI-ready pipelines must handle schema evolution explicitly with validation steps and alerting.
Idempotency is a correctness requirement. A pipeline that produces different results when run twice on the same input data – because it accumulates records rather than replacing them – will corrupt training datasets over time. Idempotent pipelines produce the same output regardless of how many times they are run on the same input, which is essential for reproducible AI training.
The primary orchestration tools for enterprise AI pipelines in 2026 are Apache Airflow (the most widely deployed open-source orchestrator), Prefect (a more developer-friendly alternative with better native error handling), dbt (for SQL-based transformation pipelines within the data warehouse), and managed orchestration services from cloud providers (AWS MWAA, Google Cloud Composer, Azure Data Factory). Emerging orchestration tools such as Dagster and Marquez are gaining traction specifically for AI/ML pipeline lineage and observability. The right choice depends on team familiarity, existing infrastructure, and the complexity of the pipeline dependency graph.
Layer 3: Data Quality and Validation
Data quality is the layer that most commonly surprises enterprise AI teams. Data that looks clean in a database view is frequently inconsistent in ways that only surface during AI-specific processing: category labels that changed meaning over time, free-text fields with wildly inconsistent formats, timestamp errors, duplicate records with conflicting values, and training data that does not reflect current operational reality.
The cost of discovering data quality problems during AI development is significantly higher than discovering them during data engineering foundation work. A data quality issue discovered in week 2 of a data engineering engagement costs a few days of remediation. The same issue discovered in week 8 of an AI development project – after the model has been trained on corrupted data – costs a full retraining cycle plus investigation time.
AI-ready data quality management covers three distinct dimensions:
Completeness and consistency checks run automatically at pipeline ingestion and transformation steps, flagging records with missing critical fields, values outside expected ranges, or format inconsistencies before they reach the consolidated store. Tools like Great Expectations, dbt tests, and Soda Core enable declarative data quality rules that run as part of the pipeline.
AI-specific data quality requirements go beyond standard BI data quality. For ML training data, class balance matters – a training dataset where 99% of records are negative examples and 1% are positive will produce a model that predicts negative on almost every case. For RAG knowledge bases, document freshness and version management matter – an outdated policy document in the corpus will cause the knowledge assistant to provide incorrect guidance. For time-series predictive models, temporal leakage matters – training data must not include information that would not have been available at prediction time in production.
Ongoing monitoring and drift detection tracks data quality metrics over time and alerts when distributions shift in ways that may affect model performance. A fraud detection model trained on pre-2024 transaction patterns may begin to drift as payment methods and fraud tactics evolve. Monitoring the input data distribution against the training data distribution is the first signal that model retraining may be required. Tools like Evidently AI, Arize, and WhyLabs provide production data monitoring capabilities specifically designed for AI system observability.
Layer 4: Feature Engineering and Feature Stores
For machine learning applications, the feature engineering layer is the bridge between raw data and model-ready inputs. Features are the specific data representations – computed attributes, aggregations, transformations of raw data – that a model uses to make predictions.
The feature store is the infrastructure that makes features available consistently both during model training and during model serving in production. Without a feature store, a common and expensive problem emerges: the features used to train the model (computed offline in a data science notebook) differ from the features computed during production serving (computed by a separate engineering team’s microservice). This training-serving skew is one of the most common sources of unexplained model performance degradation in enterprise deployments.
A feature store addresses this by centralising feature computation and serving. Features are computed once, stored in the feature store, and retrieved by both the training pipeline and the production serving system from the same source. This ensures that the model sees exactly the same feature representations in production that it was trained on.
Feature stores also provide a critical capability for regulated AI: point-in-time correctness. For any historical decision – a credit application approved or declined in Q3 2024, for example – the feature store can reconstruct exactly what feature values were available to the model at the time that decision was made. This is essential for regulatory examination of historical model decisions, which requires the ability to reproduce the exact information the model had access to.
The most widely deployed feature store options in 2026 are Feast (open-source, vendor-neutral), Tecton (managed enterprise feature store), and the native feature store capabilities in Databricks and AWS SageMaker. For regulated enterprises, Databricks Feature Store with Delta Lake’s time-travel capability provides a particularly strong point-in-time correctness implementation. For the full MLOps governance framework that surrounds feature store implementation in regulated environments, see our guide to MLOps best practices for regulated industries.
Layer 5: Data Governance, Lineage, and Access Control
Data governance is the layer that determines whether an AI programme is sustainable rather than just functional. A technically capable AI system built on ungoverned data infrastructure is a compliance liability, a security risk, and an operational fragility waiting to manifest.
AI-ready data governance covers five specific requirements that are more demanding than standard data governance for BI and reporting:
Data lineage end-to-end. For every model output – whether a prediction, a generated response, or a retrieved document – it must be possible to trace the data that produced it: which source systems contributed, which transformations were applied, which version of the data was used. This lineage chain is the audit trail that regulators, compliance teams, and business stakeholders need to trust AI-generated outputs.
Access control at the data layer. AI systems query data on behalf of users. The access controls applied to those queries must reflect the user’s permissions, not the AI system’s permissions. An AI agent with broad data access that surfaces confidential documents in responses to users who are not authorised to see them is a data breach, regardless of how well the application layer is secured. For the broader AI governance framework that data governance sits within, see our guide to AI governance for LLMs and enterprise agents.
Consent and data minimisation compliance. AI training data must comply with the consent framework under which the data was collected. Customer transaction data used to train a fraud detection model must have been collected and processed under a legal basis that permits this use. GDPR, CCPA, and equivalent frameworks impose specific constraints on AI training data that must be reflected in the data governance framework.
Retention and deletion. Training data retained beyond its governance-defined retention period creates compliance exposure. Data subject deletion requests (the right to erasure under GDPR and similar frameworks) must be implementable: if a customer requests deletion of their data, the organisation must be able to remove that data from training datasets and, where technically feasible, retrain models that incorporated it.
Cataloguing and documentation. Every dataset used in AI system development must be documented in a data catalogue: its source, schema, quality standards, access permissions, and retention policy. Undocumented datasets create governance blind spots that surface as compliance failures and operational surprises.
The Most Common Data Engineering Failures in AI Projects

Understanding the failure patterns prevents the most expensive mistakes. These are the data engineering failures that most consistently derail enterprise AI programmes.
Treating data preparation as a project task rather than an infrastructure investment. Data cleaning and preparation done once for a specific AI project does not generalise. The next project encounters the same messy data and goes through the same expensive cleanup cycle. Investing in reusable data pipelines, quality frameworks, and governance infrastructure eliminates this recurring cost.
Building for batch when the AI use case requires near-real-time data. A fraud detection model cannot use yesterday’s transaction features to detect today’s fraud. A demand forecasting model that consumes weekly inventory snapshots cannot support real-time procurement decisions. Mismatches between pipeline freshness and AI use case requirements are discovered in production, at the worst possible time. Real-time data freshness requirements are particularly acute in logistics and supply chain AI – see our guide to AI in supply chain and logistics for how real-time pipeline architecture supports demand sensing and route optimisation.
Ignoring training-serving skew. The single most common source of unexplained production performance degradation. When training features and serving features are computed by different code paths, models encounter data at serving time that differs from what they were trained on, degrading outputs without a clear diagnostic signal.
No monitoring after deployment. An AI system deployed without data quality monitoring and model performance monitoring will degrade silently. Data distributions shift, source system schemas change, upstream data quality deteriorates – and the model produces increasingly unreliable outputs without any alert triggering a review.
Starting AI development before the data foundation is established. The pattern that converts a 12-week project into a 24-week project with a doubled budget. Data engineering work done under AI development pressure is compressed, shortcuts are taken, and the resulting pipelines are fragile and difficult to extend for subsequent use cases.
Implementation Roadmap: Building an AI-Ready Data Foundation
The phased approach to building an AI-ready data foundation balances speed-to-value with investment in reusable infrastructure.
Phase 1 (Weeks 1 to 6): Data audit and foundation design. Conduct a comprehensive audit of data sources required for the prioritised AI use cases. Map source systems, assess data quality, identify gaps, and design the target architecture. Establish the cloud data warehouse and initial ingestion pipelines for the highest-priority data domains. Implement automated data quality checks on ingested data.
Phase 2 (Weeks 6 to 14): Pipeline build and governance framework. Build the transformation pipelines that produce the data structures each AI use case requires. Implement lineage tracking. Establish access controls and document data assets in a catalogue. For ML use cases, implement the feature store and validate training-serving feature consistency. For RAG use cases, build the document ingestion and chunking pipeline with metadata tagging. For the specific data pipeline architecture that RAG systems require, see our guide to RAG development for enterprise knowledge systems.
Phase 3 (Weeks 14 to 20): Monitoring, quality management, and AI deployment. Implement data quality monitoring and model performance monitoring. Launch the first AI use case on the established foundation. Use the production operation of the first use case to identify and address gaps in the data infrastructure before deploying the second.
Beyond Phase 3: Compound value from shared infrastructure. Each subsequent AI use case leverages the established foundation, adding only the incremental data pipelines and features specific to its requirements. Enterprises that build the foundation properly in Phases 1 and 2 consistently find that their second and third AI deployments are 40-60% faster and cheaper than their first, because the infrastructure investment is amortised across the growing AI portfolio.
Moweb’s Data Engineering & Foundations practice implements all five layers of AI-ready data infrastructure as a dedicated engagement phase preceding AI application development. Our team works across cloud data warehouses, real-time streaming platforms, feature stores, and data governance frameworks.
Frequently Asked Questions About Data Engineering for AI
Why do most AI projects fail due to data problems rather than model problems? Because model quality depends entirely on data quality. A sophisticated model trained on poorly prepared, inconsistent, or unrepresentative data will produce unreliable outputs regardless of its architectural sophistication. The model is the most visible component of an AI deployment and therefore receives the blame when things go wrong – but the root cause is almost always the data infrastructure beneath it. 80% or more of enterprise AI initiative failures trace back to data engineering issues, according to 2026 research, not to model limitations.
What is the difference between a data warehouse and a data lake for AI? A data warehouse stores structured, transformed data in a schema optimised for query performance. It is best for AI and analytics use cases operating on structured business data (transactions, customer records, operational metrics). A data lake stores raw, unprocessed data in its native format at low cost, including unstructured data like documents, images, and log files. A data lakehouse (Databricks, Delta Lake, Apache Iceberg) combines both patterns – structured and unstructured data in the same store, with ACID transaction support and high query performance. Most enterprise AI programmes eventually use a lakehouse architecture.
What is training-serving skew, and why does it matter? Training-serving skew occurs when the features used to train a model are computed differently from the features computed at serving time in production. This happens when training uses a data science notebook and production uses a separately implemented microservice. The result is that the model encounters feature values in production that differ from what it was trained on, degrading output quality without a clear diagnostic signal. A feature store prevents training-serving skew by centralising feature computation so training and serving draw from the same source.
How much does building an AI-ready data foundation cost? The cost varies significantly by the complexity of the source system landscape and the number of data domains required. For a mid-market enterprise with 5 to 10 key data sources, a cloud data warehouse setup, initial pipelines, quality framework, and governance documentation typically runs $80,000 to $200,000 as a dedicated engagement. This investment is typically recovered within the first AI use case through reduced development time and the elimination of the mid-project data remediation that unfounded AI projects invariably require.
What is a feature store, and does every AI project need one? A feature store is an infrastructure that centralises feature computation and serving for ML models, ensuring consistency between training and production. Not every AI project needs one: RAG-based knowledge systems and most generative AI applications do not use traditional ML features. Predictive ML applications (churn models, fraud detection, demand forecasting, credit scoring) benefit significantly from a feature store. Organisations deploying multiple ML models that share feature computations get the most value from a feature store investment.
How do we ensure data governance compliance when building AI systems? Data governance for AI requires: clear documentation of the legal basis for using each data source in AI training and inference; access controls at the data layer that reflect user permissions rather than AI system permissions; lineage tracking that traces every model output back to its source data; retention and deletion capabilities that allow compliance with data subject rights requests; and data quality monitoring that identifies compliance-relevant data issues before they affect model outputs. The governance framework should be established before AI development begins, not retrofitted after deployment.
Conclusion: The Foundation Is What Lasts
Every AI use case your organisation will ever deploy – every RAG system, every predictive model, every AI agent, every copilot – depends on the same underlying data infrastructure. The organisation that invests in that infrastructure once, correctly, has a foundation that compounds in value with every subsequent AI deployment. The one that treats data engineering as a project-by-project cleanup exercise pays the setup cost repeatedly, at each project, under pressure.
The enterprises achieving the highest AI ROI in 2026 made the same foundational decision: they treated data engineering as strategic infrastructure, not project overhead. They ran the data audit before committing the AI budget. They built the pipelines before training the models. They established governance before deploying to production.
The question is not whether your organisation needs an AI-ready data foundation. It is whether you build it proactively as a strategic investment or reactively as an emergency intervention mid-project.
Moweb’s Data Engineering & Foundations practice builds AI-ready data infrastructure for enterprises across financial services, manufacturing, healthcare, and technology sectors. Our engagements cover all five layers: ingestion and consolidation, pipelines and orchestration, data quality, feature engineering, and governance. Talk to our team about your data foundation.
Found this post insightful? Don’t forget to share it with your network!