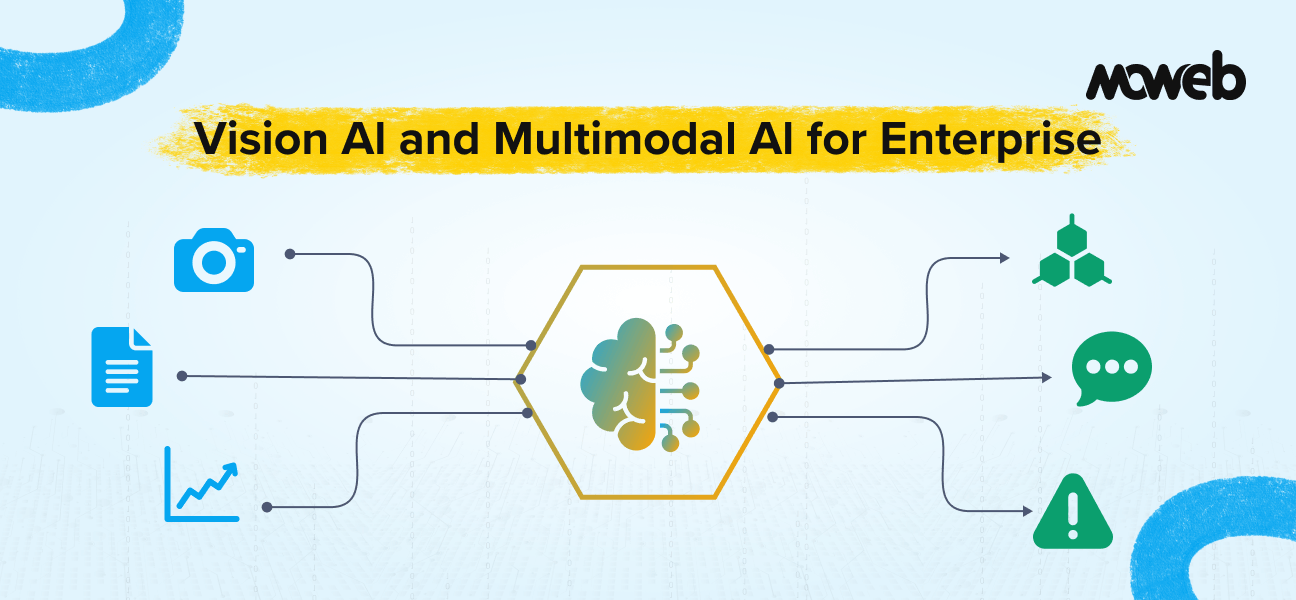
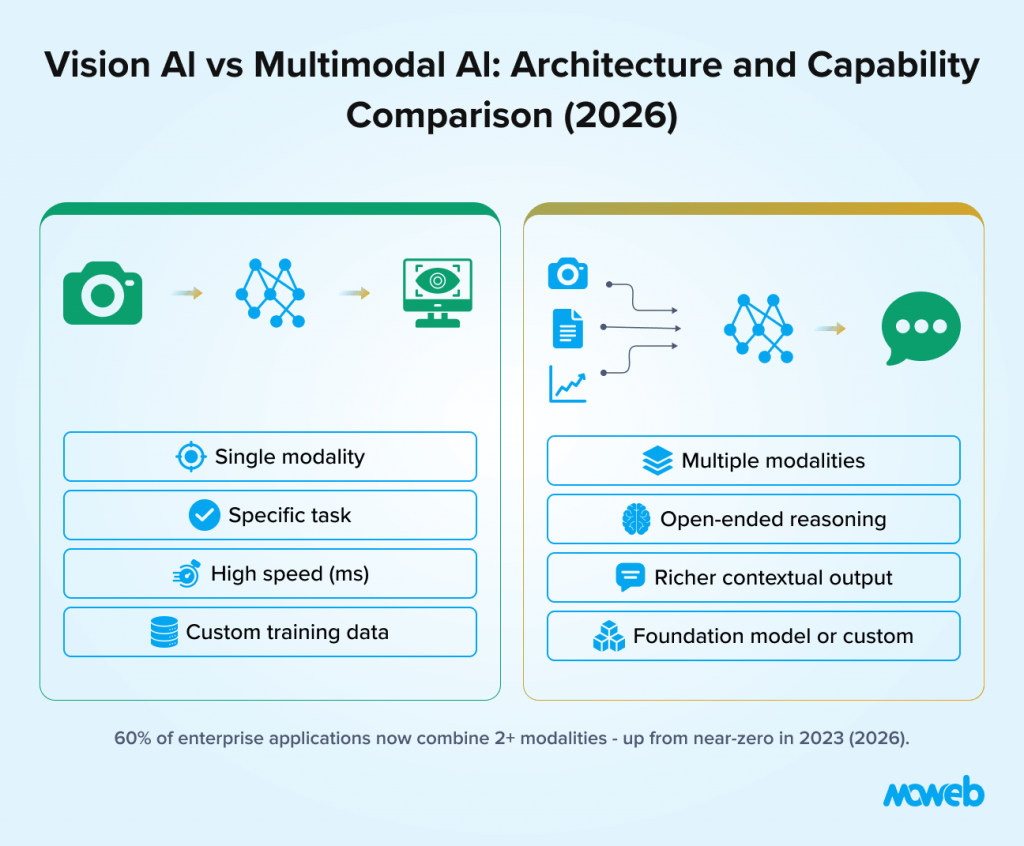
What is the difference between vision AI and multimodal AI? Vision AI (also called computer vision) refers to AI systems that process and understand visual data – images, video, and video streams – to perform tasks such as object detection, defect identification, facial recognition, and scene understanding. Multimodal AI is broader: it refers to AI systems that process and reason across two or more data types simultaneously – combining vision with text, audio, sensor data, or structured data to produce outputs that reflect cross-modal understanding. A quality inspection system that detects defects in images is vision AI. A system that looks at the same image and generates a natural-language maintenance report while cross-referencing the equipment sensor history is multimodal AI. In 2026, the two capabilities are increasingly deployed together: nearly 60% of enterprise applications are now built using models that combine two or more data modalities.
What are the most valuable enterprise use cases for vision AI in 2026? The five enterprise vision AI use cases with the strongest documented ROI in 2026 are: visual quality inspection in manufacturing (95–99.5% defect detection accuracy at production line speeds), document intelligence from scanned images and photographs (extracting structured data from non-digital source documents), field operations and maintenance support (technicians using camera input to query equipment manuals and maintenance history), retail visual search and planogram compliance monitoring, and medical imaging analysis in healthcare settings. Market sizing for computer vision varies meaningfully by methodology and scope: broader estimates put the 2026 global computer vision market at $24.14 billion (Fortune Business Insights) to $32 billion (Lasting Dynamics), while the narrower AI-based visual inspection segment specifically was valued at $1.62 billion in 2024, growing at 13.8% CAGR. Across methodologies, the consistent finding is double-digit-to-high-double-digit annual growth through the early 2030s.
For most of the history of enterprise AI, vision was a separate discipline from language. Computer vision teams built detection models on labelled image datasets. NLP teams built text models on document corpora. The two disciplines used different architectures, different toolchains, and different evaluation frameworks.
The convergence of these disciplines into multimodal AI systems that jointly process and reason across images, text, audio, video, and sensor data is one of the most significant capability expansions in enterprise AI in 2026. Nearly 60% of enterprise applications are now built using models that combine two or more data modalities, according to market research published in January 2026. About 47% of US enterprises have fully embedded multimodal AI into daily operational workflows.
The practical effect is that vision AI, which was previously the domain of specialist computer vision teams with deep ML expertise, is now accessible to enterprise development teams through foundation models (GPT-5.x with vision, Claude Opus 4.6/4.8 and Sonnet 4.6, Gemini 3.1 Pro, Qwen3-VL, and open-weight options such as LLaVA-NeXT) that handle the heavy lifting of visual understanding without requiring custom model training from scratch.
This guide covers what vision AI and multimodal AI can and cannot do for enterprise operations, the five highest-value use cases running in production in 2026, the architectural patterns that make enterprise deployments reliable and governable, and a practical starting point for organisations that are new to this capability area. For where multimodal AI sits within the broader enterprise AI capability spectrum, see our guide to the difference between AI chatbot, copilot, and AI agent.
Understanding the Capability Landscape: What Vision AI Can Do Today
The capability frontier for enterprise vision AI has moved substantially in the past 24 months. Understanding what is genuinely production-ready versus what is still emerging is the foundation for realistic scoping.
What is production-ready in 2026: Object detection and classification at industrial scale is mature technology. YOLO-family models (YOLO26 is the current generation, with architectural refinements including Progressive Loss Balancing and Small-Target-Aware Label Assignment that specifically improve detection of small and occluded defects) and similar architectures run at frame rates compatible with production line speeds, detecting and classifying objects, defects, and anomalies with documented accuracy of 95–99.5% (some sectors, including semiconductor wafer inspection and pharmaceutical blister pack inspection, exceed 98%) for well-defined defect types in controlled lighting conditions. This capability underpins qu
For context on the baseline, this is replacing: Sandia National Labs has measured that human visual inspectors miss 20–30% of manufacturing defects under real production conditions, with the best human inspectors topping out around 85% accuracy under ideal conditions that rarely hold during an overnight shift. Inter-inspector agreement on defect severity is only 55–70%, meaning identical products can receive different quality verdicts depending on which inspector reviews them. This is the gap AI visual inspection is closing, not a marginal improvement on an already-reliable process.
Document understanding from images is now accessible through vision-language models (VLMs). A photograph of a handwritten form, a scanned invoice, a photograph of an equipment nameplate, or a screenshot of a legacy system interface can be processed by a VLM to extract structured data fields without requiring OCR pipeline engineering. The accuracy for standard document types is comparable to dedicated OCR systems and significantly better for documents with variable formatting.
Visual question answering allows an enterprise application to ask a VLM questions about an image – “Is this weld joint within specification?” “What is the part number on this component?” “does this planogram match the reference layout?” – and receive a structured, actionable answer. This capability is particularly valuable for field operations, maintenance, and quality applications where the query is contextual rather than predefined.
Image and video analysis for surveillance, safety monitoring, and access control is deployed at scale across enterprise facilities, logistics operations, and public infrastructure. Detecting PPE compliance on a construction site, identifying safety violations in a warehouse, or counting occupancy in a retail space are all production-ready applications.
What is still maturing: Real-time video analysis at full production line speeds using VLMs rather than traditional computer vision models. VLMs currently have inference latency that makes them impractical for the fastest production line speeds; hybrid architectures (traditional CV for fast detection, VLM for detailed analysis of flagged frames) are the current best practice for high-speed applications.
Reliable 3D scene understanding from 2D images. Depth estimation and spatial reasoning from monocular images have improved substantially but remain less reliable than LiDAR or structured light approaches for applications requiring precise spatial measurements.
Audio-visual multimodal reasoning at enterprise scale. Combining video and audio analysis is technically possible with current foundation models but is not yet at the reliability level required for most production enterprise applications.
The Five Enterprise Vision AI Use Cases with Proven ROI

Use Case 1: Visual Quality Inspection in Manufacturing
Visual quality inspection is the most widely deployed and best-evidenced enterprise vision AI application. AI computer vision systems inspect products at production line speeds, detecting defects that human visual inspection misses and generating per-unit digital quality records that manual inspection cannot produce.
The ROI drivers are well-documented across manufacturing sectors. AI inspection achieves 95–99.5% defect detection accuracy depending on defect type and image quality, significantly above the 85% human inspection baseline under ideal conditions, and as low as 70–80% under real production conditions (Sandia National Labs). 100% inspection of production output becomes economically viable where sampling inspection was previously the only cost-effective option. Per-unit quality records support traceability requirements in automotive, aerospace, medical device, and food manufacturing contexts.
BMW Group’s AIQX (Artificial Intelligence Quality Next) system, running across all of BMW’s global plants, documents the production reality: 50% faster defect detection compared to manual inspection and roughly 40% reduction in defects. Separately, BMW’s GenAI4Q pilot, launched April 2025, uses vehicle specification and real-time production data to generate customised quality inspection plans per vehicle. More broadly, documented manufacturing deployments report 374% three-year ROI with 7–8 month average payback, and up to 10–30x first-year ROI in defect cost avoidance for the highest-impact inspection points. One counterintuitive industry finding: in many manufacturing contexts, even a model with only 50% defect detection accuracy is still net positive, because it catches defects that pure sampling-based inspection would have missed entirely.
The architecture for manufacturing visual quality inspection is typically traditional computer vision rather than VLM-based: a custom-trained detection model specific to the product type and defect taxonomy, running on edge inference hardware at the production line. Training data requirements are manageable for common defect types (500 to 2,000 labelled images per defect class, supplemented with synthetic data augmentation), and inference latency can be optimised for production line speeds. For a full treatment of AI quality inspection in the manufacturing context, see our guide to AI in manufacturing: pilot to plant-wide deployment.
A practical caution for buyers: the gap between vendor demo accuracy and real factory floor accuracy is one of the most consistent failure patterns in this category. A system achieving 98% accuracy in a controlled demo can produce 75% accuracy on an actual production line if lighting, camera angle, or product variation differs from the training conditions. Validate any vendor’s accuracy claims against your own representative production samples before committing to scale.
Use Case 2: Document Intelligence from Visual Inputs
Traditional document processing AI operates on digital text: PDFs with embedded text, structured data exports, and typed documents that OCR can reliably convert to machine-readable format. A large proportion of enterprise documents do not fit this profile: handwritten forms, photographs of physical documents, screenshots of legacy systems, scanned historical records, and field-captured images of equipment nameplates, labels, and specification plates.
Multimodal AI brings document intelligence to these visual-only document types. A VLM can process a photograph of a delivery note and extract vendor, product, quantity, and date fields. It can read a handwritten maintenance log captured on a tablet camera. It can extract the model number, serial number, and installation date from a photograph of an equipment nameplate taken by a field engineer. It can process a scanned historical record and structure its content for database entry.
The commercial impact is the elimination of manual data entry for document types that were previously excluded from digitisation programmes because of their non-standard format. Industries with high volumes of non-digital documents – field services, construction, logistics, insurance, and any organisation with extensive paper-based historical records – are the primary beneficiaries.
Use Case 3: Field Operations and Maintenance Support
Field engineers and maintenance technicians work with equipment, infrastructure, and assets that are complex, diverse, and distributed. Their primary information need at the point of work is: “what do I need to know about this specific asset, right now, to do this task correctly?”
Multimodal AI addresses this by enabling a field worker to photograph the asset they are working on and receive an immediate, contextually grounded response: “This is a Grundfos CM5-4 centrifugal pump, installed in Q3 2019. The most recent maintenance record shows impeller wear noted in March 2025. The recommended procedure for the fault you are describing is document EM-7 section 4.2.”
This capability – sometimes called visual asset intelligence or field AI – combines image recognition (identifying the asset from the photograph), RAG retrieval (pulling the relevant technical documentation and maintenance history), and generative response (composing a contextually appropriate answer). It is one of the clearest examples of multimodal AI creating value that neither computer vision nor text AI could create independently.
For a field engineer in an industrial setting, the commercial benefit is reduced time to diagnosis, reduced reliance on experienced senior technicians for routine consultations, and reduced error rate on maintenance tasks performed with insufficient documentation.
Use Case 4: Retail Visual Intelligence
Retail visual intelligence encompasses several distinct computer vision applications, each with independent commercial value.
Planogram compliance monitoring uses computer vision to compare shelf arrangements against the required planogram layout, flagging deviations (out-of-stock gaps, misplaced products, incorrect facing counts) in real time for store operations teams. Retailers using automated planogram monitoring report 15-25% reduction in out-of-stock events compared to manual periodic auditing.
Visual search allows shoppers to upload an image and find matching or similar products in the retailer’s catalogue, as described in our guide to AI in ecommerce and retail. The same vector embedding architecture underlies both capabilities.
Customer behaviour analytics uses anonymised video analysis to understand customer movement patterns, dwell time at specific fixtures, queue formation and wait times, and conversion patterns at different store locations. These analytics inform both physical store layout decisions and staffing allocation without requiring any personally identifiable data.
Use Case 5: Medical and Clinical Imaging Analysis
Medical imaging AI is one of the most mature and most regulated enterprise vision AI application areas. AI systems that analyse radiology images (chest X-ray, CT, MRI), pathology slides, and clinical photographs have been demonstrated to detect specific findings with sensitivity and specificity comparable to or exceeding specialist clinicians for defined tasks.
The regulatory context for clinical AI is demanding – FDA SaMD classification requirements, clinical validation standards, and post-market surveillance obligations apply to AI systems whose outputs influence clinical decisions, as covered in our guide to AI in healthcare operations. But within the regulated framework, medical imaging AI is generating documented clinical value: earlier detection of abnormalities, reduced missed finding rates, prioritisation of urgent cases for expedited review, and reduction in radiologist reading burden.
For healthcare organisations building AI capabilities, medical imaging is typically not a first deployment use case because of its regulatory complexity. Administrative document intelligence and clinical workflow automation are typically the appropriate starting points.
Multimodal AI Architecture: How Enterprise Systems Are Built
Understanding the architecture of enterprise multimodal AI systems helps technical leaders ask the right questions when evaluating approaches and vendors.
Architecture Pattern 1: Foundation Model API (Fastest Path)
The simplest and fastest-to-deploy multimodal AI architecture uses a hosted foundation model API, current-generation models such as GPT-5.x, Gemini 3.1 Pro, or Claude Sonnet 4.6 to handle both visual understanding and language generation. Images are submitted to the API alongside text prompts, and the model processes both jointly.
This architecture is appropriate for use cases where: the required inference latency is seconds rather than milliseconds, data sovereignty constraints permit external API processing, the visual understanding required is general (not highly specialised to a specific product or defect type), and the deployment timeline is measured in weeks rather than months.
The limitations: API cost scales with usage volume, API-based architectures introduce a dependency on the provider’s continued availability and pricing, and data sensitivity may prohibit sending images containing proprietary or regulated content to external APIs. For use cases where data sovereignty constraints prevent sending images to external APIs, see our guide to sovereign AI and on-premises model deployment for the self-hosted alternative. Open-weight VLMs including Qwen3-VL and LLaVA-NeXT variants now make self-hosted visual understanding viable for many use cases that previously required an external API.
Architecture Pattern 2: Vision-Language Model with RAG
For enterprise use cases that require grounding visual analysis in organisational knowledge – field operations, equipment intelligence, compliance checking against specifications – the appropriate architecture combines a VLM (for visual understanding) with a RAG system (for knowledge retrieval).
The workflow: the user captures an image and submits it with a text query. The VLM processes the image to extract relevant visual features and entities. The RAG system retrieves relevant documents from the enterprise knowledge base based on both the visual entities and the text query. The VLM generates a response grounded in both the visual input and the retrieved knowledge.
This is the architecture underlying field asset intelligence, visual document processing with knowledge validation, and compliance checking applications. For the RAG architecture layer, our guide to RAG development for enterprise knowledge systems covers the full technical implementation.
Architecture Pattern 3: Custom Computer Vision with Edge Deployment
For use cases requiring low-latency inference at the point of capture – production line quality inspection, real-time safety monitoring, warehouse automation – the appropriate architecture is a custom-trained computer vision model deployed on edge inference hardware close to the data source.
This architecture does not use a foundation model. It requires a labelled training dataset specific to the application, a model training pipeline, evaluation and validation against production data, edge hardware deployment (NVIDIA Jetson, Intel Neural Compute Stick, custom FPGA), and an MLOps pipeline for model monitoring and updates.
The advantage is low latency (milliseconds), no dependency on cloud connectivity, lower ongoing cost per inference at high volume, and full data sovereignty. The disadvantage is higher upfront engineering cost and the requirement for application-specific training data.
Architecture Pattern 4: Hybrid (VLM for Reasoning, CV for Detection)
For applications that require both high-speed detection and intelligent analysis – quality inspection where flagged defects require detailed characterisation, or surveillance where detected events require contextual reasoning – a hybrid architecture uses traditional computer vision for fast initial detection and a VLM for detailed analysis of flagged instances.
The fast CV model handles the real-time stream, flagging frames or events that require deeper analysis. The VLM processes flagged items with higher latency but greater analytical depth. This hybrid pattern is the current best practice for manufacturing quality inspection at high production speeds and for surveillance applications where event characterisation matters as much as detection.
Getting Started: A Practical Entry Point for Enterprise Teams
The most common question from enterprise teams new to vision AI is where to start without committing to a large infrastructure investment before understanding whether the capability delivers value for their specific use case.
Step 1: Identify the use case with the most accessible visual data and clearest success metric. The best first vision AI use case has three characteristics: you already have a body of labelled or labelable visual data (existing quality inspection records with known defect annotations, document images with known extracted fields, product images with known attributes), the success metric is specific and measurable (defect detection rate, extraction accuracy, response accuracy), and the current manual process is a known cost centre.
Step 2: Start with a foundation model API to validate the approach before investing in custom training. For most enterprise vision AI use cases, a foundation model API (GPT-4o Vision, Gemini 1.5 Pro, or Claude 3.5 Sonnet) can be used to validate whether the visual understanding approach works on your data before committing to custom model training. A structured evaluation on 50-100 representative samples – comparing API-based results against your ground truth labels – typically takes 2-3 weeks and provides enough signal to determine whether to proceed to production architecture design.
Step 3: Determine the production architecture based on the validation findings. If API-based inference is accurate enough and the latency and cost are acceptable for your production volume: API architecture with appropriate data governance controls. If latency or cost requirements favour a custom model, or if data sovereignty requirements prohibit external API processing: custom model training and edge or on-premises deployment. If the use case requires grounding visual analysis in organisational knowledge: VLM with RAG.
Step 4: Build the data pipeline and governance layer alongside the model. Vision AI governance has specific requirements: maintaining per-inference audit trails for regulated applications, managing training data versioning for model reproducibility, implementing access controls on both input images and model outputs, and monitoring for model drift as operational conditions change over time. These governance requirements should be designed into the system from the start. Our guide to MLOps best practices for regulated industries covers the model governance layer in detail.
Before committing budget to Step 2, it is worth benchmarking what a structured pilot should cost. See our breakdown of what an AI proof of concept costs in 2026 for realistic cost expectations. Vision AI pilots have specific cost drivers (image labelling volume, annotation tooling, edge hardware testing) that differ from text-only AI pilots.
Frequently Asked Questions About Vision AI and Multimodal AI for Enterprise
What is the difference between a vision-language model (VLM) and a traditional computer vision model? A traditional computer vision model is trained to perform a specific task on images: detecting objects, classifying images, or identifying defects. It produces structured outputs (bounding boxes, class labels, confidence scores) defined at training time. A vision-language model (VLM) jointly processes images and text, understanding both modalities and generating natural language outputs. VLMs are more flexible – they can answer open-ended questions about images, generate descriptions, and reason across visual and textual context – but are generally slower and more expensive per inference than task-specific CV models.
Do we need to train a custom model for enterprise vision AI, or can we use foundation models directly? It depends on the use case. For use cases requiring general visual understanding – document intelligence, visual question answering, product description generation – foundation model APIs (GPT-4o, Gemini, Claude) work well without custom training. For use cases requiring high-accuracy detection of specific, domain-specific objects or defects at production scale – manufacturing quality inspection, specialised medical imaging analysis – custom-trained models typically outperform general foundation models on domain-specific tasks and offer lower latency and cost at volume.
What data do we need to build a vision AI system? The data requirement depends on the architecture. For foundation model API approaches: representative examples for evaluation (50-200 images with ground truth labels), but no large training dataset. For custom computer vision model training: typically 500-2,000 labelled images per class for simple detection tasks, significantly more for complex multi-class or multi-attribute tasks. For multimodal RAG applications: the visual data pipeline plus the organisational knowledge base (documents, technical manuals, specifications) that the system retrieves from.
What is multimodal RAG and when is it useful? Multimodal RAG combines visual understanding with knowledge retrieval. When a user submits an image and a question, the system uses the VLM to understand the image, queries a knowledge base for relevant documents or records, and generates a response grounded in both the visual input and the retrieved knowledge. This is most useful for field operations (photograph an asset, get maintenance guidance from the knowledge base), compliance checking (photograph a configuration, check against documented specifications), and document intelligence with validation (photograph a form, extract and validate fields against reference data).
How does vision AI work in regulated industries like healthcare and financial services? Vision AI in regulated industries requires the same compliance architecture as any other AI system: data governance appropriate to the data classification (HIPAA for PHI, GDPR for personal data), model documentation and validation appropriate to the risk level of the application, audit trail generation for regulated decisions, and in healthcare, potential FDA SaMD classification for systems whose outputs influence clinical decisions. The vision modality adds specific requirements: consent for image capture where individuals are identifiable, access controls on stored images matching the sensitivity of the subjects, and in some jurisdictions, specific restrictions on facial recognition use.
What is the typical implementation timeline for an enterprise vision AI system? For a foundation model API-based document intelligence or visual QA system: 4-8 weeks from project start to production deployment. For a custom computer vision model for manufacturing quality inspection: 10-16 weeks including data collection, labelling, training, evaluation, edge deployment, and production validation. For a multimodal RAG application combining visual understanding with knowledge retrieval: 8-14 weeks depending on the complexity of the knowledge base integration. These timelines assume clean, accessible data and no significant legacy system integration complexity.
What accuracy gap should we expect between a vendor demo and our actual production environment? Expect a meaningful gap unless the vendor has validated specifically on your data. A system demonstrating 98% accuracy on a vendor’s curated demo set can fall to 75% or lower on an actual production line if lighting conditions, camera positioning, product variation, or surface characteristics differ from the training distribution. Always require validation on 50–200 of your own representative samples before scaling any vision AI deployment, and treat vendor-supplied accuracy figures as a ceiling rather than an expectation until independently confirmed.
Conclusion: Vision and Language Are Converging – Enterprise Deployments Should Reflect That
The most significant shift in enterprise AI in 2026 is not the emergence of better individual models. It is the convergence of vision and language understanding into single systems that reason across both modalities simultaneously. The enterprise application that photographs a piece of equipment and immediately retrieves contextually appropriate maintenance guidance – combining computer vision, RAG, and language generation in a single interaction – was not practically achievable without custom research two years ago. It is a standard architecture pattern today.
This convergence means that enterprises planning AI programmes should design for multimodal capability from the start, even if their first deployment is text-only. The data infrastructure, the vector database, the RAG pipeline, and the governance framework that support a text-based knowledge assistant can be extended to support visual inputs without rebuilding from scratch. The organisations that build multimodal-ready infrastructure in 2026 will deploy their next capability in weeks rather than months.
Moweb’s Vision AI & Multimodal AI practice designs and builds enterprise multimodal AI systems across manufacturing, field services, healthcare, and retail applications – from custom computer vision model development through to VLM-based multimodal RAG architectures. Talk to us about your vision AI requirements.
Found this post insightful? Don’t forget to share it with your network!